Amazon Bedrock AgentCore: Building Production-Ready AI Agents on AWS
Quick summary: Amazon Bedrock AgentCore solves the production gaps in Bedrock Agents API: persistent memory, tool reliability, and agent observability. Here is the architecture guide.
Key Takeaways
- Amazon Bedrock AgentCore solves the production gaps in Bedrock Agents API: persistent memory, tool reliability, and agent observability
- import { Image } from 'astro:assets'; Building a Bedrock agent prototype takes a few days
- Amazon Bedrock AgentCore is the runtime layer AWS built to address those three failure modes
- It does not replace the Bedrock Agents API — it wraps it with production-grade infrastructure
- Understanding what AgentCore adds, and why those additions are necessary, is the starting point for any enterprise AI agent deployment
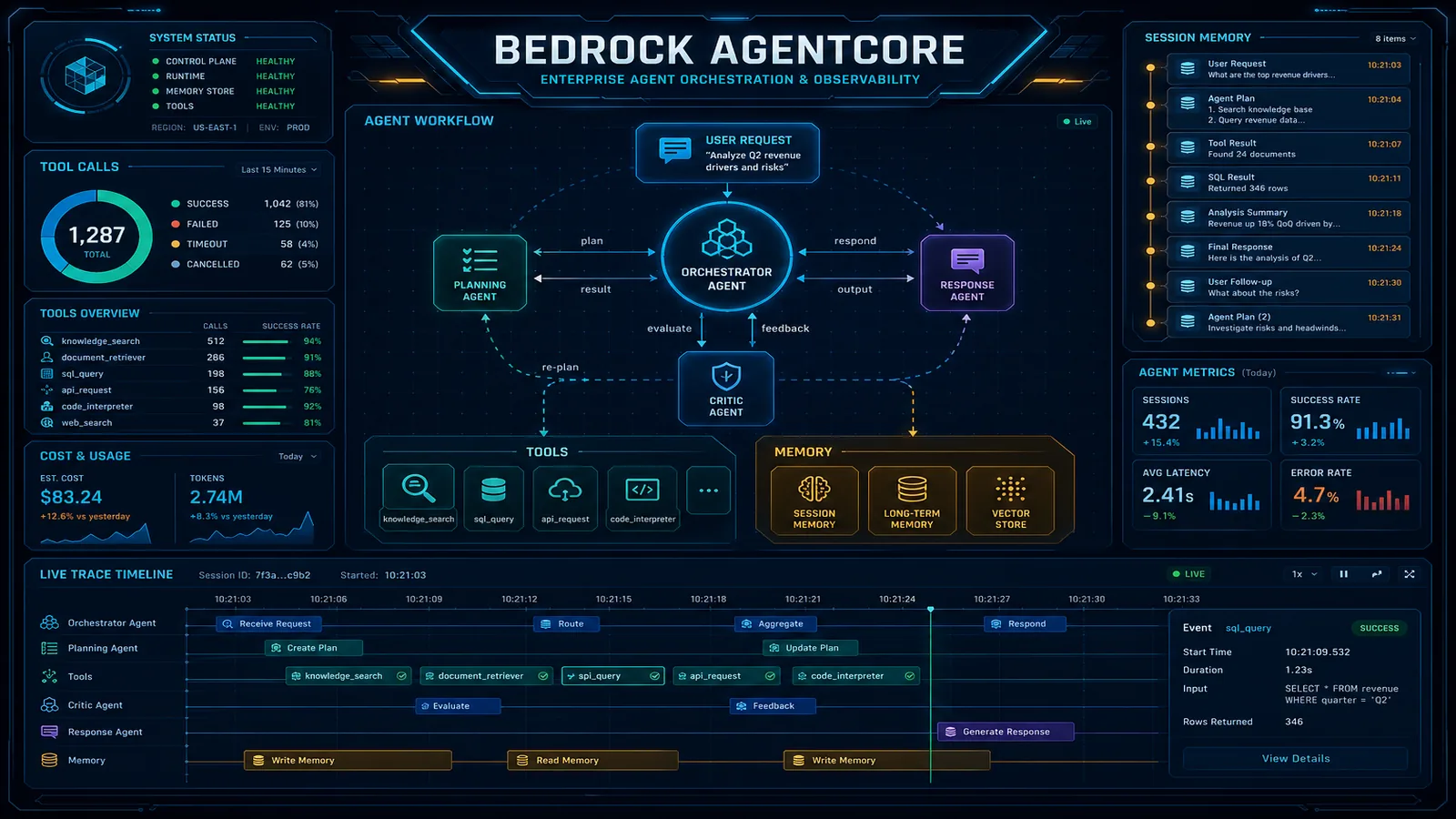
Table of Contents
Building a Bedrock agent prototype takes a few days. Moving it to production reliably takes months — unless you understand why the prototype approach breaks at production scale and what AgentCore does to fix it.
The Bedrock Agents API handles the core agent loop: send a prompt to an LLM, route tool calls to action groups or knowledge bases, process results, and continue until the agent produces a final response. This works well in controlled demos. It breaks in production at three specific points: state management between sessions, tool execution reliability, and the complete absence of observability into agent reasoning.
Amazon Bedrock AgentCore is the runtime layer AWS built to address those three failure modes. It does not replace the Bedrock Agents API — it wraps it with production-grade infrastructure. Understanding what AgentCore adds, and why those additions are necessary, is the starting point for any enterprise AI agent deployment.
What AgentCore Adds That the Bedrock Agents API Doesn’t
The Bedrock Agents API is a stateless request-response service. Each InvokeAgent call is independent. The API handles LLM routing, knowledge base retrieval, and action group invocation within a single session, but it has no memory across sessions and no infrastructure to manage tool execution reliability or capture agent reasoning for audit.
| Capability | Bedrock Agents API | AgentCore Runtime |
|---|---|---|
| LLM model routing | Yes | Yes (via underlying Bedrock Agent) |
| Knowledge Base retrieval | Yes | Yes (via underlying Bedrock Agent) |
| Action group invocation | Yes (direct Lambda call) | Yes (managed execution with retry + timeout) |
| In-session conversation memory | Yes (session attributes) | Yes (enhanced, scoped namespaces) |
| Cross-session persistent memory | No | Yes (DynamoDB-backed memory store) |
| Agent reasoning traces | Minimal (step trace attribute) | Full structured traces in CloudWatch |
| Distributed tracing (X-Ray) | No | Yes |
| Sandboxed code execution | No | Yes (AgentCore Code Interpreter) |
| VPC-isolated execution | Limited | Full VPC endpoint support |
| Tool execution retry + circuit breaker | No (Lambda handles it independently) | Yes (configurable at AgentCore level) |
The comparison makes the division of responsibility clear: the Agents API handles the intelligence layer (model routing, knowledge retrieval, tool calling logic), and AgentCore handles the operational layer (state persistence, execution reliability, observability).
Agent Memory Architecture
AgentCore Memory has two distinct types that serve different purposes in the agent lifecycle.
In-session memory is conversation context within a single agent invocation session. This is scoped to a sessionId and includes the conversation history, intermediate tool results, and any facts the agent has extracted from the current conversation. In-session memory is held in-process and is lost when the session ends. The Bedrock Agents API already provides basic session-level state via sessionAttributes, but AgentCore enhances this with structured memory namespaces that make it easier to retrieve specific context without passing the entire conversation history in every prompt.
Cross-session memory is persistent state that survives across sessions. It is stored in a DynamoDB-backed AgentCore Memory Store and indexed by a memoryId that typically maps to a user or account identifier. When a new session starts, AgentCore retrieves the relevant cross-session memory and injects it into the agent’s context before the first model call.
The memory architecture for a production enterprise AI assistant looks like this:
┌─────────────────────────────────────────────────────────────┐
│ New Session: User ID = "user_12345" │
│ │
│ 1. AgentCore retrieves cross-session memory │
│ memoryId: "user_12345" │
│ → {"preferred_currency": "USD", │
│ "last_project": "Project Phoenix", │
│ "risk_tolerance": "moderate"} │
│ │
│ 2. Memory injected as context prefix to agent prompt │
│ │
│ 3. Agent processes conversation │
│ Session ID: "session_abc123" │
│ → In-session memory tracks this conversation's state │
│ │
│ 4. On session end: AgentCore extracts significant facts │
│ and writes them back to cross-session memory store │
│ (configurable extraction prompt + merge rules) │
└─────────────────────────────────────────────────────────────┘Configuring memory namespaces controls isolation: you can have separate memory namespaces for different agent capabilities (a “user preferences” namespace vs. a “project context” namespace), with different TTLs and access policies per namespace.
import boto3
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
# Invoke agent with AgentCore memory enabled
response = bedrock_agent_runtime.invoke_agent(
agentId='AGENT_ID',
agentAliasId='ALIAS_ID',
sessionId='session_abc123',
memoryId='user_12345', # Cross-session memory key
enableTrace=True,
inputText='What was the status of the project I was asking about?',
)
# AgentCore automatically retrieves cross-session memory for user_12345
# and injects it as context before the model callThe memoryId parameter is the trigger: when you include it, AgentCore handles memory retrieval and injection automatically. When the session closes, AgentCore’s configured memory consolidation logic extracts key facts from the conversation and persists them back to the memory store.
Tool Integration and Reliability
The Bedrock Agents API calls action groups directly — if a Lambda action group times out or throws an exception, the agent receives an error and must decide how to handle it. There is no built-in retry, no circuit breaker, and no dead-letter path. For production workloads where action groups call external APIs or databases that have intermittent availability, this means agent failures are frequent and silent.
AgentCore wraps action group execution with a configurable reliability layer:
{
"actionGroupExecutionConfig": {
"retryPolicy": {
"maxAttempts": 3,
"retryableErrorCodes": ["THROTTLING", "SERVICE_UNAVAILABLE"],
"backoffStrategy": "EXPONENTIAL",
"initialDelayMs": 200
},
"timeoutConfig": {
"timeoutSeconds": 30,
"onTimeoutBehavior": "RETURN_ERROR_TO_AGENT"
},
"circuitBreaker": {
"enabled": true,
"failureThreshold": 5,
"recoveryTimeSeconds": 60
}
}
}The RETURN_ERROR_TO_AGENT timeout behavior is significant: rather than failing the entire agent invocation when a tool times out, AgentCore returns a structured error to the agent’s reasoning chain and lets the model decide how to proceed. A well-prompted agent will either retry with a simpler tool call, fall back to an alternative tool, or inform the user that the specific data source is temporarily unavailable — instead of hanging or crashing.
AgentCore Code Interpreter is a separate capability: a sandboxed Lambda execution environment for running arbitrary Python code generated by the agent. This is the mechanism for agents that need to perform data analysis, calculations, or data transformations that are too complex to express as tool parameters. The sandbox prevents the generated code from accessing filesystem resources, network addresses outside an allowlist, or AWS credentials — making code execution safe to expose to end users.
Observability: Tracing Agent Reasoning Chains
Before AgentCore, understanding why a Bedrock agent produced a particular response required parsing the trace field in the InvokeAgent response — a nested JSON structure with limited structure and no standardized format for querying or alerting.
AgentCore emits structured agent traces to CloudWatch Logs in a schema-consistent format, and distributed traces to X-Ray. A trace for a single agent turn includes:
- Model invocation: the prompt sent to the model, the model’s text response, token counts, and latency
- Tool selection: which tool the model decided to call and why (the model’s reasoning text)
- Tool execution: the tool call parameters, execution duration, response payload, and whether it was a first attempt or a retry
- Memory operations: memory retrieval calls (what was fetched, latency) and memory write calls (what was persisted)
- Final response generation: the prompt used to generate the final user-facing response
Here is what a failed-and-recovered tool call looks like in the CloudWatch trace:
{
"traceId": "trace_abc123",
"sessionId": "session_abc123",
"step": 3,
"type": "TOOL_INVOCATION",
"toolName": "get_account_balance",
"attempt": 1,
"status": "FAILED",
"errorCode": "THROTTLING",
"durationMs": 5003,
"retryScheduledInMs": 400
},
{
"traceId": "trace_abc123",
"sessionId": "session_abc123",
"step": 3,
"type": "TOOL_INVOCATION",
"toolName": "get_account_balance",
"attempt": 2,
"status": "SUCCESS",
"durationMs": 312,
"result": {"balance": 48392.50, "currency": "USD"}
}The step number stays consistent across retry attempts, so you can reconstruct the full reasoning chain even when retries occur. In X-Ray, each tool invocation appears as a child span of the parent agent invocation span, making it straightforward to identify which tool is contributing most to total agent latency.
For compliance-sensitive use cases — financial advice, healthcare information, legal document review — the structured traces are also the audit trail. Every model reasoning step and every tool invocation is logged with timestamps and can be queried with CloudWatch Logs Insights:
fields @timestamp, step, toolName, attempt, status, durationMs
| filter sessionId = "session_abc123"
| sort @timestamp ascProduction Deployment Pattern
A production enterprise AI assistant built on AgentCore follows this architecture:
Infrastructure stack:
-
Bedrock Agent (the intelligence layer) — defines the system prompt, action groups, and Knowledge Base connections. The agent is the cognitive configuration; it does not change frequently.
-
AgentCore Runtime (the operational layer) — configured with memory namespaces (cross-session per user), action group reliability policies, Code Interpreter enablement, and VPC configuration.
-
Lambda action groups — the tools the agent calls. These remain standard Lambda functions; AgentCore wraps their invocation rather than replacing them.
-
DynamoDB (AgentCore Memory Store) — the persistence layer for cross-session memory. Managed by AgentCore; you do not interact with this table directly.
-
API Gateway + Lambda (the application layer) — your application routes user requests to AgentCore via the
InvokeAgentAPI, passing the authenticated user’smemoryIdand a session-scopedsessionId.
Deployment sequence:
import boto3
import json
bedrock_agent = boto3.client('bedrock-agent')
# Step 1: Create the AgentCore runtime configuration
# (Attach to existing Bedrock Agent)
runtime_config = {
'agentId': 'EXISTING_AGENT_ID',
'memoryConfiguration': {
'enabledMemoryTypes': ['SESSION_SUMMARY'],
'storageDays': 30,
'sessionSummaryConfiguration': {
'maxRecentSessions': 5
}
},
'actionGroupExecutionConfig': {
'retryPolicy': {
'maxAttempts': 3,
'backoffStrategy': 'EXPONENTIAL'
},
'timeoutSeconds': 30
}
}
# Step 2: Create AgentCore alias pointing to the configured runtime
response = bedrock_agent.create_agent_alias(
agentId='EXISTING_AGENT_ID',
agentAliasName='production-v1',
description='Production alias with AgentCore memory and retry',
routingConfiguration=[{
'agentVersion': 'DRAFT'
}]
)
alias_id = response['agentAlias']['agentAliasId']
# Step 3: Invoke through AgentCore runtime
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
def invoke_agent_for_user(user_id: str, session_id: str, user_message: str):
response_stream = bedrock_agent_runtime.invoke_agent(
agentId='EXISTING_AGENT_ID',
agentAliasId=alias_id,
sessionId=session_id,
memoryId=f'user_{user_id}', # Cross-session memory key
enableTrace=True,
inputText=user_message,
)
full_response = ''
for event in response_stream['completion']:
if 'chunk' in event:
full_response += event['chunk']['bytes'].decode('utf-8')
elif 'trace' in event:
# Forward trace to CloudWatch (automatic) or custom handler
process_trace(event['trace'])
return full_responseThe critical design decision is the memoryId mapping: use a stable, user-specific identifier that your application can reliably associate with the authenticated user. For enterprise applications with SSO, this is typically the IdP subject identifier or an internal user UUID — not a session token (which rotates).
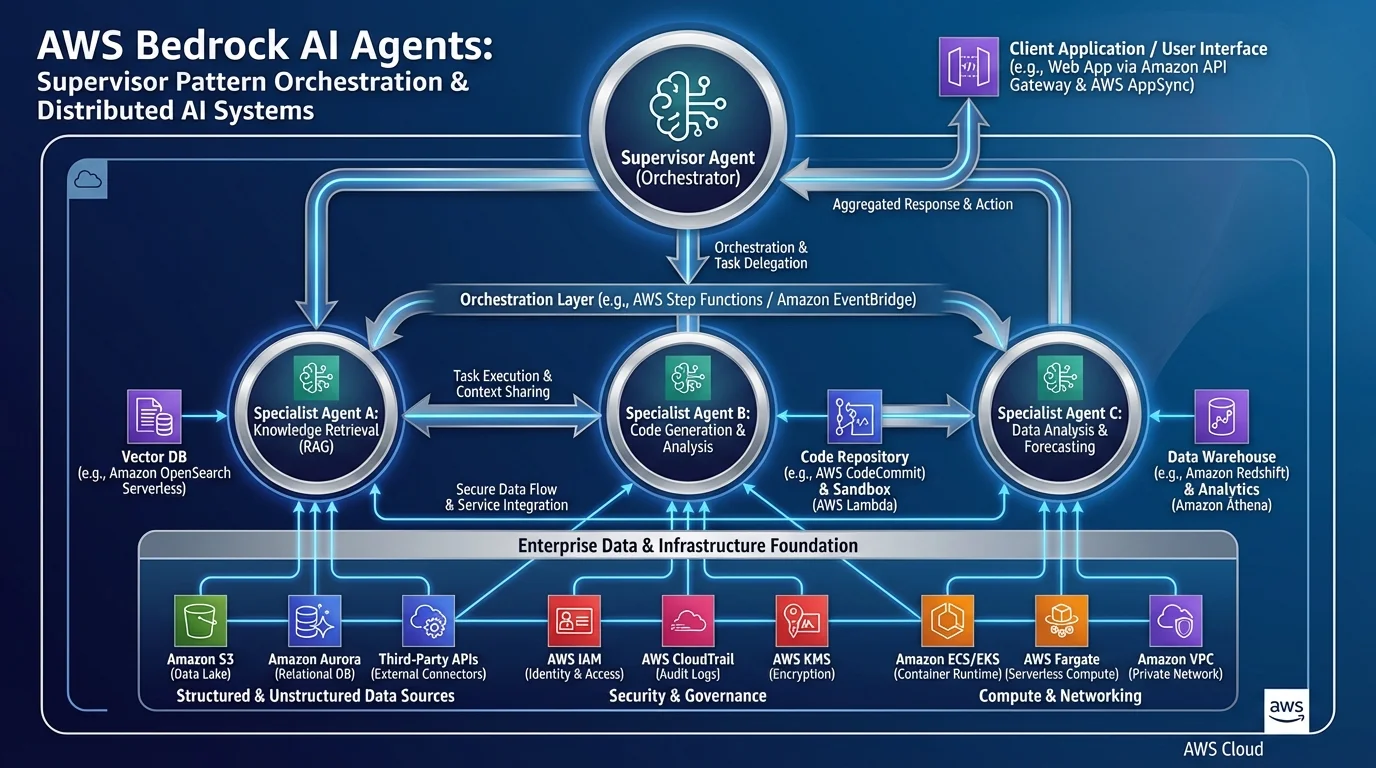
Multi-Agent Patterns with AgentCore
AgentCore is the right runtime for multi-agent architectures where a supervisor agent delegates tasks to specialized sub-agents. The AgentCore observability layer stitches together the trace across the entire call chain:
Supervisor Agent (AgentCore runtime)
├── Route: "research question" → Research Sub-Agent (AgentCore runtime)
│ ├── Tool: search_knowledge_base
│ └── Tool: fetch_document
├── Route: "financial calculation" → Finance Sub-Agent (AgentCore runtime)
│ └── Tool: run_calculation (Code Interpreter)
└── Final synthesis prompt → User responseX-Ray connects the spans across agent boundaries, so a single trace ID follows the request from supervisor to sub-agent and back. Without AgentCore, instrumenting this distributed call chain requires custom trace propagation code in every Lambda function.
For a detailed breakdown of the supervisor-delegate multi-agent pattern, see AWS Bedrock Multi-Agent Supervisor Pattern. For the foundational Bedrock Agents API concepts, see AWS Bedrock AI Agents and Agentic Workflows. For where AgentCore fits in the broader 2026 AWS AI service landscape, see the Top 20 AWS AI Services guide.
Need help moving your Bedrock agent from prototype to production? FactualMinds has helped enterprise teams design and deploy AgentCore-backed AI assistants with proper memory architecture, observability, and VPC isolation. We bring hands-on delivery experience from complex multi-agent systems in financial services, healthcare, and enterprise SaaS environments. Reach out to scope a production readiness assessment.
Related reading
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.