Top 20 AWS AI & Modern Services in 2026: Enterprise Adoption Guide
Quick summary: The 20 AWS services reshaping enterprise architecture in 2024–2026: AI agents, vector storage, generative BI, distributed SQL, and security automation explained.
Key Takeaways
- The 20 AWS services reshaping enterprise architecture in 2024–2026: AI agents, vector storage, generative BI, distributed SQL, and security automation explained
- The 20 AWS services reshaping enterprise architecture in 2024–2026: AI agents, vector storage, generative BI, distributed SQL, and security automation explained
Table of Contents
AWS released over 200 service updates and launches in 2025 alone. For an enterprise architect, reading the re:Invent announcement firehose and the AWS blog is not a strategy — it is noise management. The services that actually change architecture decisions are a small fraction of that total, and they get lost in the volume.
This guide filters the 2024–2026 AWS launch period down to 20 services with material enterprise impact. “Material” means: a service that changes how you would design a new architecture today, or that gives you a credible path to decommission a component in an existing architecture. EC2, S3, Lambda, RDS, and VPC are excluded — not because they are unimportant, but because they have deep existing coverage and did not undergo category-level changes in this window.
Every service listed here is either Generally Available or in a widely-available preview with documented production adoption. Each entry includes a production use case and an internal link to a dedicated deep-dive guide.
How We Selected These 20 Services
Selection criteria, applied strictly:
GA or widely-available preview. Services in limited preview with closed access are excluded. We need you to be able to actually use these.
Material architecture impact. A “material” change means: it eliminates a separate infrastructure component you would otherwise provision, it changes the cost structure of an existing workload by more than 20%, or it enables a capability class that was not previously available on AWS at all.
Genuinely new capability vs. feature update. A new S3 storage class or an additional CloudFront edge location is a feature update. A native vector storage primitive built into S3 is a new capability. We apply this filter aggressively.
Demonstrated enterprise production adoption. At minimum, one publicly-available reference architecture, case study, or re:Invent talk from an enterprise customer. Services with zero enterprise public references are treated as speculative regardless of how interesting the capability is.
Twenty services passed all four filters. Here they are.
Section 1: AI Agent Infrastructure
The most consequential shift in enterprise AWS architecture over the past 18 months is not model capability — it is the maturation of the infrastructure layer that makes AI agents production-viable. Three services define this layer.
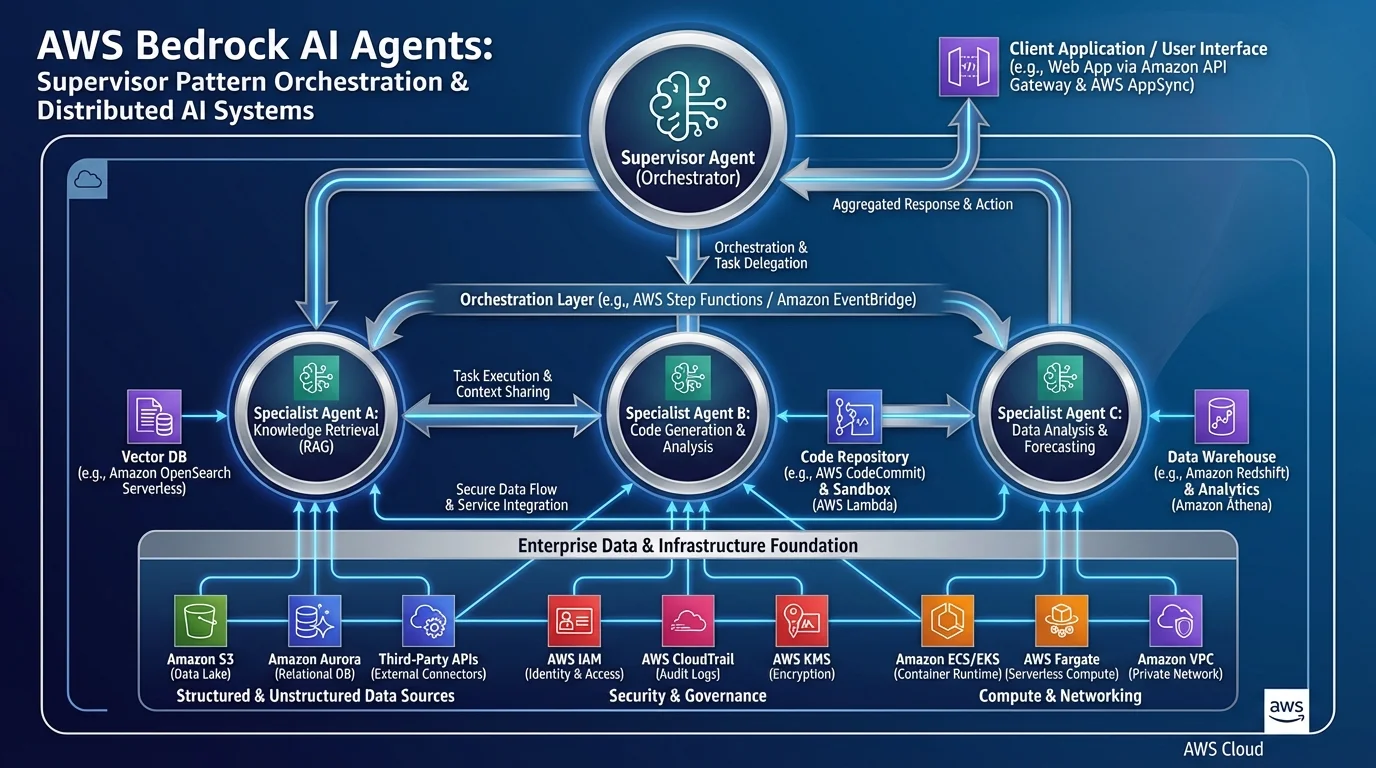
1. Amazon Bedrock AgentCore
The Bedrock Agents API gives you LLM-powered tool-calling and knowledge base retrieval. Amazon Bedrock AgentCore is the runtime layer that makes those agents production-viable — it adds persistent memory (both in-session and cross-session), managed tool execution with configurable retry and timeout policies, and agent observability through CloudWatch traces and X-Ray distributed tracing.
The production problem AgentCore solves is specific: enterprises building Bedrock agent prototypes consistently hit the same wall when moving to production. Session state is lost between conversations. Tool invocations fail silently or timeout with no retry. There is no way to trace why an agent chose a particular tool chain. AgentCore addresses all three.
Production use case: A financial services firm building a client-facing portfolio review agent needs the agent to remember a client’s previously stated risk tolerance across sessions (cross-session memory), handle Bloomberg API timeouts gracefully (managed tool retry), and audit every agent reasoning step for compliance review (CloudWatch traces). AgentCore handles all three. The alternative is a custom DynamoDB session store, a Lambda wrapper with exponential backoff logic, and a custom trace aggregation pipeline — weeks of undifferentiated infrastructure work.
→ Full AgentCore architecture guide
2. Amazon Bedrock Flows
Amazon Bedrock Flows is a visual multi-step AI workflow builder with a node-based graph model. Node types include Prompt (model invocation), Retrieval (Knowledge Base query), Agent (Bedrock Agent call), Lambda (custom code), Condition (branching), Iterator/Collector (map-reduce over arrays), and Storage (S3 read/write).
The key architectural distinction: Flows is not a replacement for Step Functions. It is purpose-built for AI workflows where every node either invokes an AI model, queries a knowledge base, or routes data between those operations. Flows has a 15-minute execution limit and does not support human approval steps — anything outside those constraints belongs in Step Functions.
Production use case: A legal services company needs to process incoming contract PDFs through a four-step pipeline: extract key clauses (Bedrock Data Automation), run a clause analysis prompt (Prompt node with Claude), check if any clause triggers a compliance flag (Condition node), and route flagged contracts to an SQS queue for legal review while storing clean contracts to S3. This entire pipeline is a single Bedrock Flow — no Lambda orchestration code, no Step Functions state machine, and it runs in under 30 seconds per document.
3. Amazon Bedrock Data Automation
Amazon Bedrock Data Automation replaces fragmented Textract + Comprehend + Lambda document processing pipelines with a managed intelligent document processing (IDP) service. BDA processes PDFs, Word documents, images, audio files, and video — and returns structured JSON output following a Blueprint schema that you define.
The critical capability that separates BDA from Textract is semantic extraction. Textract extracts text and tables from where they appear on a page. BDA uses LLM-enhanced extraction to understand the semantic meaning of content and map it to schema fields — so “Vendor” in the schema might be populated from “Supplier Name:”, “Bill From:”, or “Issued By:” depending on what the document uses.
Production use case: A healthcare insurer processing 50,000 prior authorization forms per month. Forms come from dozens of different providers with different layouts, field naming conventions, and even handwritten annotations on scanned documents. A BDA Blueprint defines the canonical fields: patient_id, diagnosis_code, requested_procedure, treating_physician, authorization_date. BDA handles the layout variance — Textract required separate extraction models per form type.
→ Full Bedrock Data Automation guide
Section 2: Foundation Models and AI Chips
Model access, multimodal generation, and the infrastructure to run models cost-effectively.
4. Amazon Nova Canvas + Reel
Amazon Nova Canvas (image generation) and Nova Reel (video generation) are AWS-native multimodal foundation models available through Bedrock. They are relevant to enterprise teams not primarily because of creative use cases, but because they eliminate the need for third-party image/video generation API contracts and the associated data processing agreements.
For enterprises with strict data residency and confidentiality requirements, the ability to generate product imagery, training data synthetic images, or video content summaries within the AWS environment — without data leaving your AWS account — is a compliance enabler. Nova Canvas supports inpainting, outpainting, and image conditioning; Nova Reel supports text-to-video and image-to-video generation up to 6 seconds.
→ Full Nova Canvas + Reel enterprise guide
5. Third-Party Models on Bedrock Marketplace
Bedrock Marketplace is the single most underrated procurement efficiency in this list. It gives enterprises access to Llama 3, Mistral Large, Cohere Command R+, AI21 Jamba, and dozens of other third-party foundation models — all through the Bedrock API, under the AWS customer agreement, billable to your AWS account.
The procurement impact: no separate vendor contracts for each model provider, no separate data processing agreements, no separate billing relationships, and no separate audit scope. For enterprises that have already completed a cloud security review and data classification process for AWS, Bedrock Marketplace models are in-scope by extension. The alternative — direct API contracts with four or five different model providers — requires legal review cycles for each.
→ Full Bedrock Marketplace guide
6. AWS Trainium2 + Inferentia2
Trainium2 and Inferentia2 are AWS-designed chips optimized for AI training and inference respectively. The headline number is 40–60% cost reduction versus equivalent GPU-based inference — but the real story is throughput-per-dollar at sustained production load.
For enterprises running large-scale inference workloads (customer-facing AI, batch document processing, embedding generation pipelines), GPU instances on standard SageMaker or EC2 are frequently the top AI cost line item. Inferentia2 instances (inf2 family) support Llama 2/3, Mistral, and custom models compiled with AWS Neuron SDK. Trainium2 instances (trn2 family) are targeted at organizations fine-tuning large models on proprietary data rather than training from scratch.
Adoption note: Using Inferentia2 requires model compilation with the Neuron SDK, which adds an initial engineering investment of 1–2 weeks depending on model architecture. Teams running standard Bedrock-managed models do not need to engage with Neuron directly.
→ Full Trainium2 + Inferentia2 guide
7. Kiro IDE
Kiro is AWS’s agentic coding assistant IDE, positioned as a step beyond GitHub Copilot. Rather than single-line or block completions, Kiro operates in “spec mode” — you describe a feature in natural language, Kiro generates a spec document (user stories, acceptance criteria, architecture notes), and then implements the spec across multiple files with full context of your codebase.
The enterprise relevance: Kiro integrates with AWS service configurations natively, making it significantly more useful for AWS-heavy codebases than general-purpose coding assistants. IaC generation, Lambda function scaffolding, CDK pattern completion, and CloudFormation template analysis are all first-class capabilities.
Section 3: Data and Storage
Four services that change the data architecture for AI-native enterprises.
8. Amazon S3 Vectors
Amazon S3 Vectors introduces a new S3 resource type — a vector bucket — that stores vector embeddings alongside metadata and supports approximate nearest-neighbor (ANN) queries. It eliminates the dedicated vector database for workloads that don’t require sub-10ms query latency.
The economic argument is straightforward: OpenSearch Serverless (the previous default vector store for Bedrock Knowledge Bases) charges per OpenSearch Compute Unit (OCU) with a minimum of 2 OCUs — roughly $700/month minimum even at low utilization. S3 Vectors charges per GB stored and per query, with typical RAG workloads running at 5–15% of equivalent OpenSearch Serverless cost.
Limitation to understand clearly: S3 Vectors query latency is 50–200ms, compared to under 10ms for in-memory vector stores. For interactive chatbots, this latency is typically acceptable. For real-time recommendation engines or sub-100ms API SLAs, it is not.
9. Amazon DataZone
Amazon DataZone is AWS’s enterprise data governance and catalog service. It provides a business data catalog (searchable by business users, not just data engineers), data access subscriptions (a data consumer requests access to a dataset, a data producer approves), and integrated data quality and lineage tracking.
For enterprises with distributed data lake architectures across multiple AWS accounts, DataZone is the governance layer that was previously missing or implemented with bespoke tooling. It integrates with Glue, Redshift, S3, Athena, and SageMaker — which means the same catalog covers structured data warehousing, data lake queries, and ML feature stores.
Why this matters for AI adoption: Enterprises that try to build AI applications without a governed data catalog consistently hit the same problem — AI developers don’t know which datasets exist, which are authoritative, who owns them, or whether they are cleared for AI training use. DataZone solves the discovery and access governance problem before you build the AI application.
10. Amazon Neptune Analytics
Amazon Neptune Analytics combines graph database queries (openCypher, Gremlin) with vector similarity search in a single service. The practical significance: knowledge graphs with embedded entity representations that support both structural queries (“find all entities connected to this customer within 3 hops”) and semantic queries (“find entities semantically similar to this description”) without data duplication.
For enterprise AI applications — particularly those involving knowledge graph RAG, fraud detection, or supply chain analysis — Neptune Analytics eliminates the need to maintain separate graph and vector stores that must be kept synchronized.
→ Full Neptune Analytics guide
11. Amazon Aurora Limitless Database
Aurora Limitless solves horizontal SQL scaling without application-level sharding. It extends Aurora PostgreSQL with a distributed transaction layer — you write standard SQL, and Aurora Limitless routes queries across shards transparently. The target workload: transactional databases exceeding what a single Aurora writer instance can handle (typically >1M write transactions/second or storage approaching 128TB).
The architectural significance: enterprises that currently manage application-level sharding logic (routing keys, cross-shard queries, rebalancing) in their Aurora PostgreSQL clusters can migrate to Limitless and eliminate that complexity entirely. This is not a storage scaling solution (Redshift handles that) — it is a write-throughput scaling solution for OLTP.
Section 4: AI-Enhanced Analytics and Developer Tools
12. Amazon Q in QuickSight
Amazon Q in QuickSight enables natural language querying of business intelligence dashboards. Business users type questions in plain English — “show me revenue by region compared to last quarter” — and QuickSight generates the appropriate visualization. This is different from AI-generated SQL (which requires data engineer involvement) — Q in QuickSight operates on the existing semantic layer that BI teams already maintain.
The enterprise adoption barrier for BI has always been the translation gap between business questions and SQL/dashboard navigation. Q in QuickSight eliminates that gap for governed datasets without requiring data engineers to write custom NL-to-SQL pipelines.
Important constraint: Q in QuickSight works best when your QuickSight datasets have well-defined column descriptions, field labels, and calculated metrics. Organizations with poorly documented data models get poor query quality. The service amplifies the quality of your existing semantic layer — it does not replace it.
→ Full Amazon Q in QuickSight guide
13. AWS Application Composer
AWS Application Composer is an AI-assisted IaC generation tool integrated into the AWS Console and VS Code. It generates CloudFormation and SAM templates from natural language descriptions, and provides a visual canvas for designing serverless architectures that exports directly to deployable IaC.
The practical use case for enterprise teams: accelerating the scaffolding phase of new service construction. Rather than writing boilerplate IAM roles, API Gateway configurations, and SQS-to-Lambda event source mappings from scratch, Application Composer generates a working template in minutes. Engineers then review and refine rather than author from scratch.
→ Full Application Composer guide
Section 5: Caching, Memory, and ML Platform
14. Amazon MemoryDB with Vector Search
Amazon MemoryDB with Vector Search adds vector similarity search to MemoryDB for Redis — AWS’s durable, Redis-compatible in-memory database. This enables storing vectors in the same data store as session data, user profiles, and real-time state — without maintaining a separate vector index.
The key differentiator from S3 Vectors and OpenSearch: MemoryDB provides sub-millisecond query latency (true in-memory execution) with durability guarantees (data survives node failure via Multi-AZ replication log). For AI workloads that require real-time vector lookup with low latency — live recommendation engines, real-time personalization, session-scoped RAG — MemoryDB is the appropriate choice. It is more expensive than S3 Vectors but significantly cheaper than running OpenSearch Serverless purely for real-time vector queries.
→ Full MemoryDB Vector Search guide
15. Amazon SageMaker Unified Studio
Amazon SageMaker Unified Studio consolidates the previously fragmented SageMaker surface area — Studio Classic, Canvas, Data Wrangler, Feature Store, Model Registry, Pipelines — into a single unified IDE. The operational significance for enterprise ML teams is that it eliminates the context-switching and permission management overhead of navigating separate SageMaker tools.
For new SageMaker adopters, Unified Studio is the right starting point. For existing teams on Studio Classic, the migration path is well-documented with a side-by-side transition period. The unified permission model (integrated with IAM Identity Center) simplifies the multi-team access control problem that was a frequent complaint with Studio Classic.
→ Full SageMaker Unified Studio guide
Section 6: Security and Compliance
Three services that collectively modernize the enterprise security control plane.
16. Amazon Verified Permissions
Amazon Verified Permissions is a managed authorization service built on Cedar — AWS’s open-source policy language for fine-grained, attribute-based access control. The service decouples authorization logic from application code: your applications make real-time authorization API calls to Verified Permissions instead of embedding permission checks in business logic.
The enterprise significance: as applications become more complex and multi-tenant, authorization logic embedded in application code becomes a liability. Cedar policies are auditable, testable, and centralizable. Verified Permissions handles policy storage, evaluation, and audit logging — your application calls IsAuthorized(principal, action, resource) and gets a binary allow/deny response in milliseconds.
Production use case: A multi-tenant SaaS platform where each tenant has custom role definitions, resource-level permissions, and time-bounded access grants. Implementing this in application code requires complex conditional logic that is difficult to audit. In Verified Permissions, it is a set of Cedar policies that a security team can review, test independently, and version-control.
→ Full Verified Permissions guide
17. Amazon Security Lake
Amazon Security Lake normalizes security telemetry from AWS services, third-party tools, and custom sources into the Open Cybersecurity Schema Framework (OCSF) and stores it in a centralized S3-based data lake in your own account. It is the infrastructure that makes security analytics scalable: rather than each SIEM tool maintaining its own data format and ingestion pipeline, Security Lake provides a single canonical representation queryable by Athena, OpenSearch, or your existing SIEM.
The cost model is compelling: Security Lake stores data in S3 with Intelligent-Tiering and exposes it via Lake Formation for access control. This is dramatically cheaper than traditional SIEM ingestion pricing (which is typically per-GB-ingested into a managed service). The tradeoff is that querying requires your own analytics tooling rather than a managed detection platform.
18. Amazon Inspector v2
Amazon Inspector v2 provides agentless vulnerability scanning for EC2 instances, container images in ECR, and Lambda function code and dependencies. The agentless model for EC2 scanning (via SSM inventory) eliminated the previous requirement to deploy and maintain an Inspector agent on every instance.
The Lambda scanning capability is the most underappreciated: Inspector v2 continuously analyzes Lambda function packages for known CVEs in bundled dependencies, and alerts when a new vulnerability is published for a dependency version your function already uses. For organizations with dozens or hundreds of Lambda functions, this eliminates the manual dependency audit cycle.
Section 7: Infrastructure Modernization
19. AWS Clean Rooms
AWS Clean Rooms enables multiple organizations to run joint analytics on combined datasets without either party exposing raw data to the other. Participants contribute tables to a Clean Room, define query rules (which columns are allowed, what aggregation thresholds prevent individual-level disclosure), and run analyses against the combined dataset — with results only returned if they meet the privacy thresholds.
The enterprise use cases are data partnerships that have historically been legally complex: retail media networks (retailer + advertiser combining purchase and campaign data), healthcare research consortia (hospital + pharmaceutical company combining clinical and trial data), and financial services risk sharing (banks comparing fraud patterns without sharing customer records).
20. Amazon Elastic VMware Service (EVS)
Amazon Elastic VMware Service runs VMware vSphere environments natively on AWS infrastructure without requiring you to re-platform or re-architect VMware workloads. Unlike VMware Cloud on AWS (which ran on dedicated bare-metal nodes managed by VMware/Broadcom), EVS runs in AWS-managed infrastructure with standard VPC networking and IAM integration.
The driver for enterprise interest is straightforward: Broadcom’s acquisition of VMware and subsequent licensing restructuring increased on-premises VMware costs significantly for many enterprises. EVS provides a migration path that preserves VMware tooling and operational familiarity while moving to AWS-managed infrastructure — without requiring immediate re-platforming of VMware workloads to EC2 or containers.
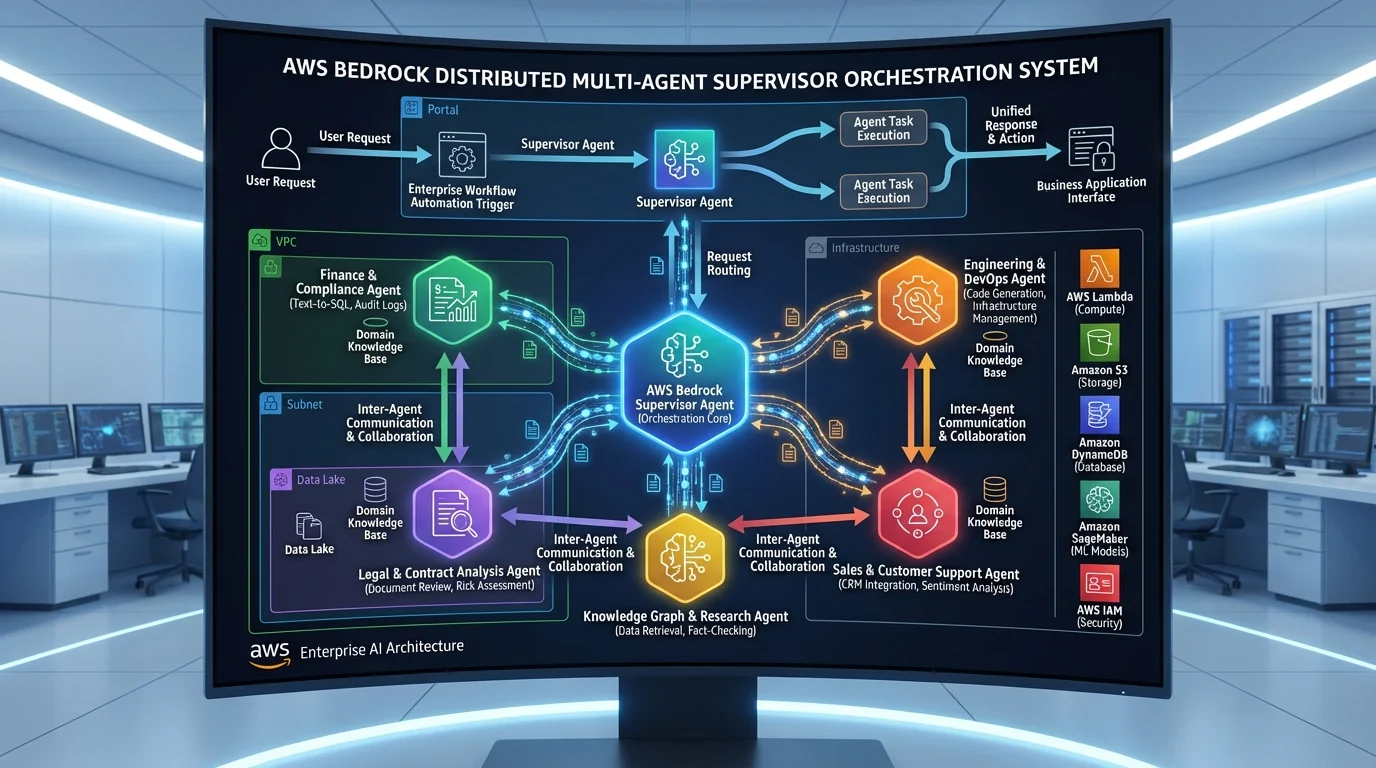
How These Services Connect: Enterprise AI Platform Reference Architecture
The 20 services above are not independent building blocks — several of them compose into a coherent enterprise AI platform. Here is the layered architecture:
Data Foundation Layer
- Amazon DataZone provides the governed data catalog. Business analysts and AI engineers discover available datasets, understand ownership and classification, and request access through DataZone subscriptions.
- Amazon Security Lake centralizes security telemetry in OCSF format, queryable via Athena. This gives the security team visibility into data access patterns without requiring bespoke log aggregation.
Storage and Retrieval Layer
- Amazon S3 Vectors stores document embeddings for RAG workloads where query latency of 50–200ms is acceptable and cost optimization is a priority.
- Amazon MemoryDB with Vector Search handles session-scoped retrieval where sub-millisecond latency matters — for example, real-time context injection into an active user conversation.
- Amazon Neptune Analytics handles knowledge graph traversal + semantic similarity for use cases involving entity relationships (org charts, supply chains, compliance hierarchies).
AI Workflow Layer
- Amazon Bedrock Flows orchestrates multi-step pipelines: document intake → Bedrock Data Automation extraction → Prompt analysis → conditional routing.
- Amazon Bedrock AgentCore provides the runtime for stateful agents that operate over multiple sessions with persistent memory, managed tool execution, and full observability.
Authorization and Compliance Layer
- Amazon Verified Permissions enforces fine-grained, auditable access control across all AI-facing APIs — who can invoke which agent, with access to which knowledge bases.
- Amazon Inspector v2 continuously scans the Lambda functions, container images, and EC2 instances running the AI infrastructure.
The architectural narrative: DataZone governs what data the AI can access. Security Lake monitors how it is accessed. S3 Vectors and MemoryDB store what the AI remembers. Bedrock Flows and AgentCore define what the AI does. Verified Permissions enforces what the AI is allowed to do.
Adoption Sequencing
| Business Goal | Primary Services | Recommended Sequence |
|---|---|---|
| Build production AI agents | AgentCore, Bedrock Flows, S3 Vectors, Bedrock Marketplace | Marketplace (model access) → S3 Vectors (knowledge store) → Bedrock Flows (pipeline) → AgentCore (production runtime) |
| Modernize data governance before AI | DataZone, Security Lake, Q in QuickSight | Security Lake (telemetry foundation) → DataZone (catalog + access control) → Q in QuickSight (governed AI analytics) |
| Secure the AI platform | Verified Permissions, Security Lake, Inspector v2 | Inspector v2 (continuous scanning) → Security Lake (centralized telemetry) → Verified Permissions (authorization layer) |
| Migrate VMware to AWS | Elastic VMware Service | EVS (lift-shift) → then evaluate EC2 re-platforming per workload |
| Reduce AI inference costs | Trainium2, Inferentia2 | Inferentia2 for existing inference workloads → Trainium2 if fine-tuning |
| Modernize document processing | Bedrock Data Automation, Bedrock Flows | BDA (extraction) → Bedrock Flows (pipeline orchestration) |
| Scale transactional database | Aurora Limitless | Benchmark current Aurora writer → migrate to Limitless if >800K writes/sec |
| Enable cross-org analytics | Clean Rooms | Define data partnership scope → configure Clean Room → run joint analysis |
Closing: A Framework for Ongoing Evaluation
AWS will launch another 200+ service updates in 2026. A sustainable evaluation process applies the same four criteria used to build this list: GA status or credible preview, material architecture impact, genuinely new capability (not a feature update), and demonstrated enterprise production reference.
Services that pass those filters warrant a dedicated spike. Services that don’t should go into a backlog for re-evaluation in 6 months. The goal is not to adopt every new service — it is to adopt the small fraction that materially improve your architecture before your competitors do.
Need help building an adoption roadmap for your specific architecture? FactualMinds has helped enterprise teams assess, prioritize, and implement exactly these services as an AWS Select Tier Consulting Partner. We can compress a 6-month evaluation cycle into a structured 4-week architecture review.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.