Biggest Mistakes Teams Face During an AWS Migration (and How to Dodge Them)
Quick summary: Nine recurring program mistakes still show up in 2026 reviews—especially after AWS closed Migration Hub to new customers on November 7, 2025. Practical fixes tied to AMS (MGN), DMS, AWS Transform, Org/SCPs, FinOps bubble costs, and the Migration Lens checklist.
Key Takeaways
- Nine recurring program mistakes still show up in 2026 reviews—especially after AWS closed Migration Hub to new customers on November 7, 2025
- Practical fixes tied to AMS (MGN), DMS, AWS Transform, Org/SCPs, FinOps bubble costs, and the Migration Lens checklist
- May 2026
- Recommendations cite published AWS pathways dated or version-stable at link time (Application Migration Service, Database Migration Service, Migration Lens, Organizations SCP concepts)
- Mistake 1 — Migrating before the multi-account / SCP backbone exists Failure mode

Table of Contents
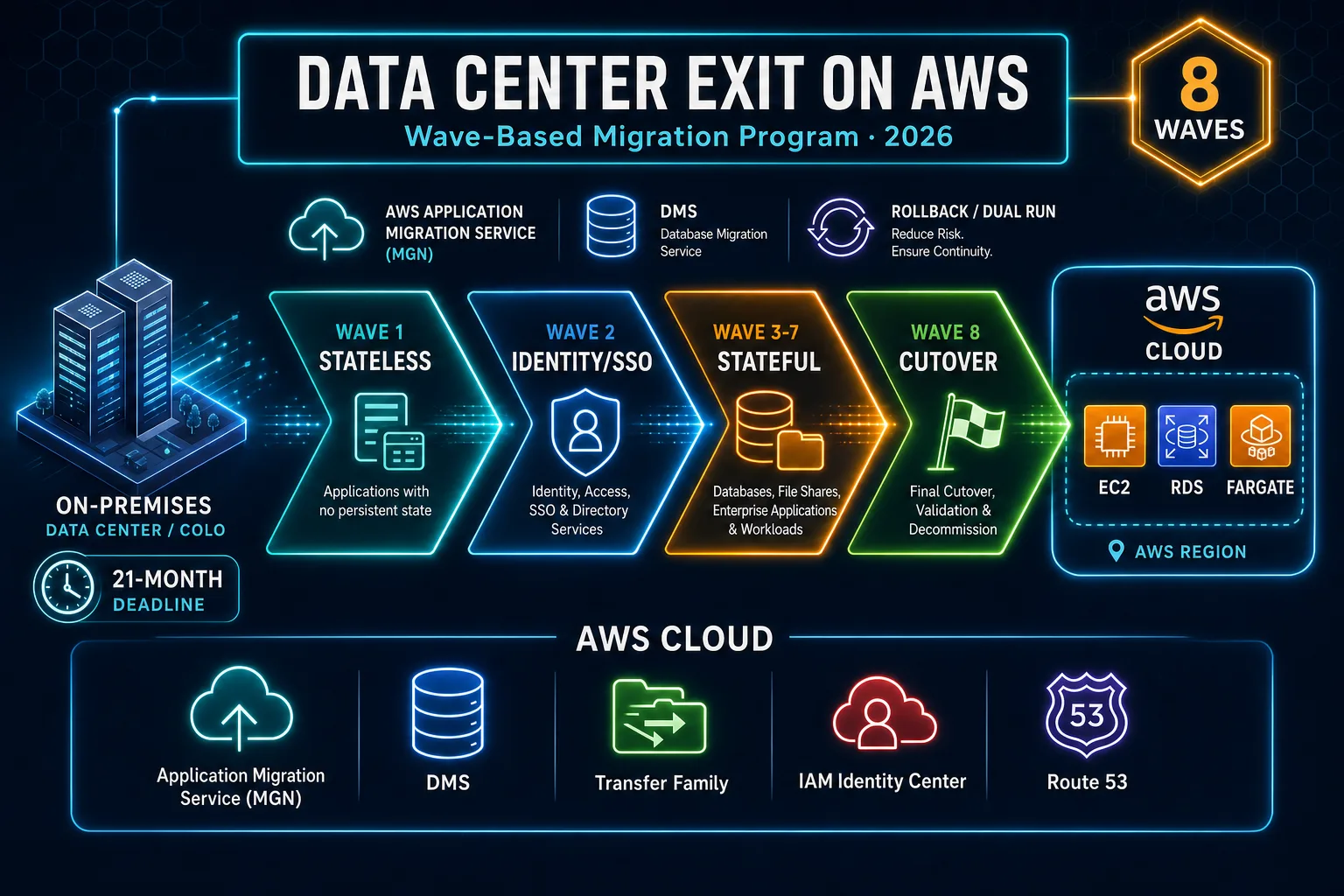
May 2026. If your architecture review still opens with “we already know our apps—start cutting over,” you are not wrong that speed matters; you are wrong that undocumented dependencies become cheaper after the first outage. The bigger shift in the last year is product-level: AWS Migration Hub is no longer open to new customers as of November 7, 2025—AWS points net-new planning at AWS Transform for comparable discovery and modernization paths. Net-new runbooks that default to Migration Hub onboarding without that caveat are already stale.
This post names nine mistakes we still see in architecture reviews and MOU workshops—framed with what breaks, what to do instead, and where the advice fails. It is not a substitute for your compliance pack or contractual RTO/RPO—it is an execution-level gut check.
Recommendations cite published AWS pathways dated or version-stable at link time (Application Migration Service, Database Migration Service, Migration Lens, Organizations SCP concepts).
Composite review pattern — Many mid-market software and shared-services portfolios we review share a common silhouette: VMware or mixed hypervisors, dozens to low hundreds of stateful VMs, insistence that “engineering already knows flows,” NAT-heavy egress, dual stacks during parallel run—and finance surprise shows up first in networking and NAT line items rather than EC2 SKU choice. Figure is illustrative, assembled from repeating themes—not a cited metric for any single tenant.
Quantified grounding for leadership slides: use current figures from the official Migration Acceleration Program page and downloadable partner/customer documentation—incentive structures and eligible services change; do not round “typical credits” from memory.
Mistake 1 — Migrating before the multi-account / SCP backbone exists
Failure mode. Applications land into a heroic “experiment” account without central logging, SCP guardrails for newly risky APIs, consistent break-glass, or segregation for prod vs non-prod. Six months later, every refactor is a tenancy migration.
Mitigation. Stand up Organizations, logging archive, delegated admin for security services, baseline SCPs for deny patterns you cannot afford even during migration chaos—then attach workloads (Organizations policy concepts).
Where this hurts velocity. Oversized SCP design before workloads exist can block legitimate sandbox automation. Start with narrowly scoped SCPs aligned to CIS-style guardrails—not a hundred bespoke denies per app team.
For sequencing strategy with the migration Rs, revisit Choosing the Right AWS Migration Strategy.
Mistake 2 — Skipping machine-readable dependency evidence
Failure mode. Sticky notes substitute for topology. Cutover rehearsal passes in staging, fails in prod because batch feeder #3 never listed DNS.
Mitigation. Treat discovery as a product deliverable: owners, application groups, connection maps, data-class tags. AWS Transform is the current AWS-side umbrella for AI-assisted inventory and modernization planning where Migration Hub net-new onboarding does not apply post-November 7, 2025 (Transform getting started). Pair with your CMDB truth source—Transform accelerates; it does not replace contracts with app owners.
Counter-case. Small 10–20 VM estates with one architect who truly holds the graph can run lean—document the exception in the risk register.
Mistake 3 — Defaulting every workload to rehost (lift-and-shift)
Failure mode. Everything lands on Amazon EC2 as a 1:1 VM clone. You gain exit from the datacenter but keep undifferentiated heavy lifting—patch cadence, license friction, static scaling.
Mitigation. Classify every candidate with the 7 Rs (see our migration strategy guide). Use AWS Application Migration Service for batch rehost where replication-based cutover fits; schedule modernization waves after stable bills and observability exist.
Where lift-and-shift still wins. Regulated cutover windows, third-party ISV binaries you cannot touch, or evidence that refactor-first invalidates support contracts.
Mistake 4 — Database cutover without rehearsal-grade DMS discipline
Failure mode. Teams assume native backups equal continuous replication. Cutover Sunday hits CDC lag, collation mismatch, or sequence drift.
Mitigation. Run AWS DMS tasks (or engine-native blue/green where supported) through full fail-forward and fail-back drills. Measure RPO under load, not idle.
When DMS is the wrong flex. Tiny databases where native snapshot + short outage is contractually acceptable—over-automation costs calendar time.
Mistake 5 — NAT gateway and cross-AZ traffic “surprises” while parallel-running
Failure mode. Dual environments, chatty microservices, default routes through NAT, cross-AZ fan-out for “HA,” no interface endpoints for heavy AWS APIs—Cost Explorer spikes while leadership still focuses on instance sizes.
Mitigation. Model data transfer and NAT as first-class line items before cutover (Cost Optimization Pillar). Add endpoints where policy allows; align AZ affinity for chatty tiers; set Cost Anomaly Detection before parallel run. Our migration cost surprises piece expands the FinOps bubble.
Mistake 6 — “Cloud security” as VM security group copy-paste
Failure mode. Broad security groups, secrets in user-data, shared instance roles, no AWS Secrets Manager rotation story, IMDSv1 tolerance.
Mitigation. Re-express controls with IAM roles per workload, least-privilege task roles, Secrets Manager or Parameter Store hierarchy, VPC endpoints for sensitive API paths, and GuardDuty/Config delegated admin from day one—not “after migration stabilizes.”
Mistake 7 — Roadmaps that still treat Migration Hub as the default for new programs
Failure mode. Third-party SOWs say “Phase 1: activate Migration Hub.” New customers cannot follow that path after November 7, 2025 per AWS documentation.
Mitigation. Update procurement templates: AWS Transform for planning/modernization assistance; Application Migration Service for lift-and-shift execution; DMS for databases; MAP where funding applies—see MAP SMB practical guide for qualification realism.
Existing Migration Hub tenants should plan only what their signed architecture allows—no blind rip-and-replace.
Mistake 8 — MAP tags and chargeback afterthoughts
Failure mode. Eligible spend never maps to MAP-approved tags; finance cannot reconcile partner incentives; engineering blames “paperwork” while credits slip a quarter.
Mitigation. Define tag policy during wave zero, align service owners before first large bill, automate CUR dashboards, and rehearse monthly MAP evidence collection with whoever signs the partner attestation (MAP overview).
Mistake 9 — Cutover waves sequenced by team politics, not dependency graph
Failure mode. Friendly teams go first; identity and payments stacks go last—but everything hid behind that AD connector you have not migrated.
Mitigation. Build a critical path DAG: identity, DNS, observability buses, shared databases, integration buses—then hang business applications. Publish the graph; defend it in steering.
When “modernize before move” is the wrong religion
Counter-case we have seen approved — A batch settlement platform with a fixed regulatory freeze could not absorb large refactors pre-cutover. The right play was AMS rehost into a locked VPC, read-only observability parity, and a post-go-live refactor program with budget reserved—not six months of blocked migration for ideal microservices.
Opinionated substitutes (use with eyes open)
| Anti-pattern | Prefer (when conditions hold) | Trade-off |
|---|---|---|
| Lift everything with ad-hoc scripts | Application Migration Service replication + launch templates | Agent footprint and change control on source hypervisors |
| Snapshot-only DB stories | DMS or engine-native blue/green with measured RPO | Operational complexity of replication |
| Default public egress for AWS APIs | VPC interface endpoints where policy allows | Endpoint hourly + data processing charges |
| Single prod account for “speed” | Workload accounts + SCP guardrails | Up-front landing zone effort |
Reproduce the guardrails (no mystery URLs)
Reproduce this — Run an AWS Well-Architected Migration Lens workload review in-console after each major wave; export notes to your program wiki. Cross-check service retirement assumptions against AWS service lifecycle communications and product pages such as Application Migration Service (note the Transform callout in the AMS guide—keep tooling names synchronized with your runbooks).
Legacy trap: runbooks that still install AWS Server Migration Service (SMS) agents. SMS is not the current lift-and-shift path AWS documents for these scenarios—default to Application Migration Service and verify current availability in your partition (commercial vs GovCloud) against official guides such as Migration tools for application mobility.
What to do this week
- Inventory every external design doc for “Migration Hub phase 1” language—update with November 7, 2025 policy or retire it.
- Route net-new portfolio planning questions to AWS Transform + Migration Lens evidence, not forum posts from 2023.
- Model NAT, cross-AZ, and endpoint costs for parallel run with Cost Anomaly Detection enabled—see migration cost surprises.
- Rehearse one DMS or blue/green fail-forward with production-like RPO measurement.
- Align MAP tagging with finance before the next major funding checkpoint—MAP SMB guide if you qualify that path.
If you only do one thing
Publish a single dependency graph with named owners and cutover order—then defend it in steering. Everything else (tools, credits, endpoints) hangs off that graph.
Related reading
- How to choose the right AWS migration strategy — 7 Rs and sequencing.
- AWS migration without cost surprises — parallel-run FinOps.
- MAP guide for SMBs — incentive realism.
- How to evaluate an AWS managed services provider — when outside delivery helps.
- When you need an AWS MSP — guardrails vs staff aug.
What this post does not cover
- Industry-specific compliance mapping (HIPAA, PCI) beyond pointing to your control matrix.
- VMware Cloud on AWS commercial negotiations or partner-specific MAP math—verify with AWS and your partner SA.
- Region-by-region service availability; features differ—validate in Service endpoints lists before cutover weekends.
- DMS Fleet Advisor or other narrowly scoped tooling beyond a general DMS rehearsal—confirm current GA/deprecation notices in AWS documentation before adopting new inventory agents.
Need a second pair of eyes on wave planning, landing zone guardrails, or MAP evidence? FactualMinds is an AWS Select Tier Consulting Partner—tell us what you are migrating.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.