High-Throughput Event Processing on AWS (2026): SQS, Kinesis, MSK, and Flink Tier Selection With Cost-Cliff Math
Quick summary: On a composite ingest workload (~8k ordered TPS, 1 KB payloads), staying on SQS FIFO without high-throughput mode capped effective throughput near 300 TPS/API and modeled queue backlog cost near $95/mo before ops time — enabling high-throughput FIFO or switching to Kinesis on-demand changed the ceiling, not the consumer code.
Key Takeaways
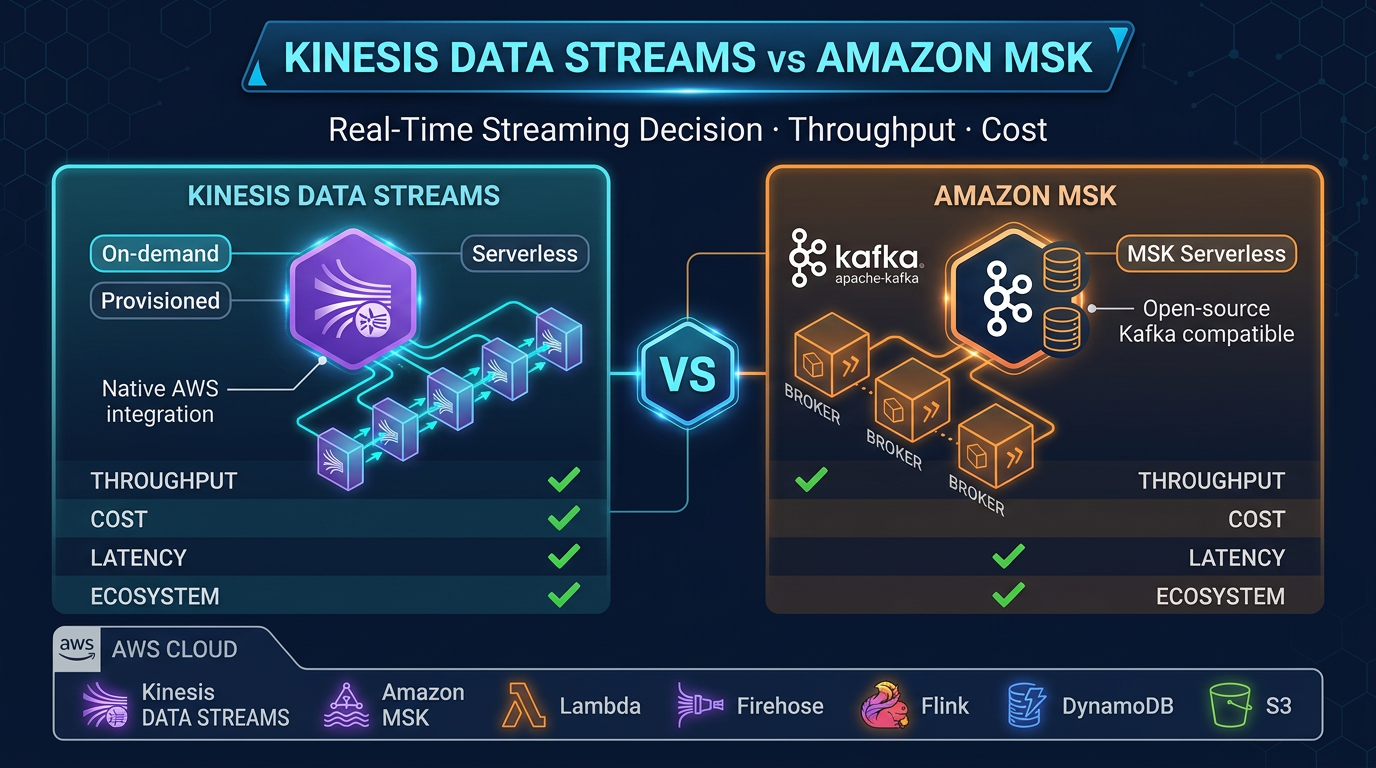
- On November 25, 2025, AWS raised the per-stream enhanced fan-out consumer limit on Kinesis Data Streams to 50 — each consumer gets a dedicated 2 MB/s read pipe instead of sharing the shard read cap
- It is not the Kinesis vs MSK platform pick alone, not sync vs async boundaries, not SQS reliability patterns, not the Kinesis→Lambda→DynamoDB reference pipeline, and not JVM runtime throughput tuning
- Phase 1 used SQS FIFO without high-throughput mode — effective ceiling ~300 TPS/API action, backlog age peaked ~14 min, modeled FIFO line ~$95/mo plus on-call time
- Phase 2 enabled high-throughput FIFO with 50 message groups — same business TPS, backlog age < 30 s, modeled line ~$118/mo
- Tier 1 — SQS: request economics beat broker hours AWS documents nearly unlimited throughput on SQS Standard queues

Table of Contents
On November 25, 2025, AWS raised the per-stream enhanced fan-out consumer limit on Kinesis Data Streams to 50 — each consumer gets a dedicated 2 MB/s read pipe instead of sharing the shard read cap. That change matters because many “we need MSK for throughput” conversations are really consumer fan-out problems, not Kafka protocol problems.
This post is the throughput tier ladder — when to stay on SQS, when Kinesis on-demand wins, when MSK is worth broker hours, and when Managed Service for Apache Flink is compute, not transport. It is not the Kinesis vs MSK platform pick alone, not sync vs async boundaries, not SQS reliability patterns, not the Kinesis→Lambda→DynamoDB reference pipeline, and not JVM runtime throughput tuning.
Artifacts: throughput tier decision matrix, throughput cost model CSV. Pricing math uses SQS calculator assumptions where applicable.
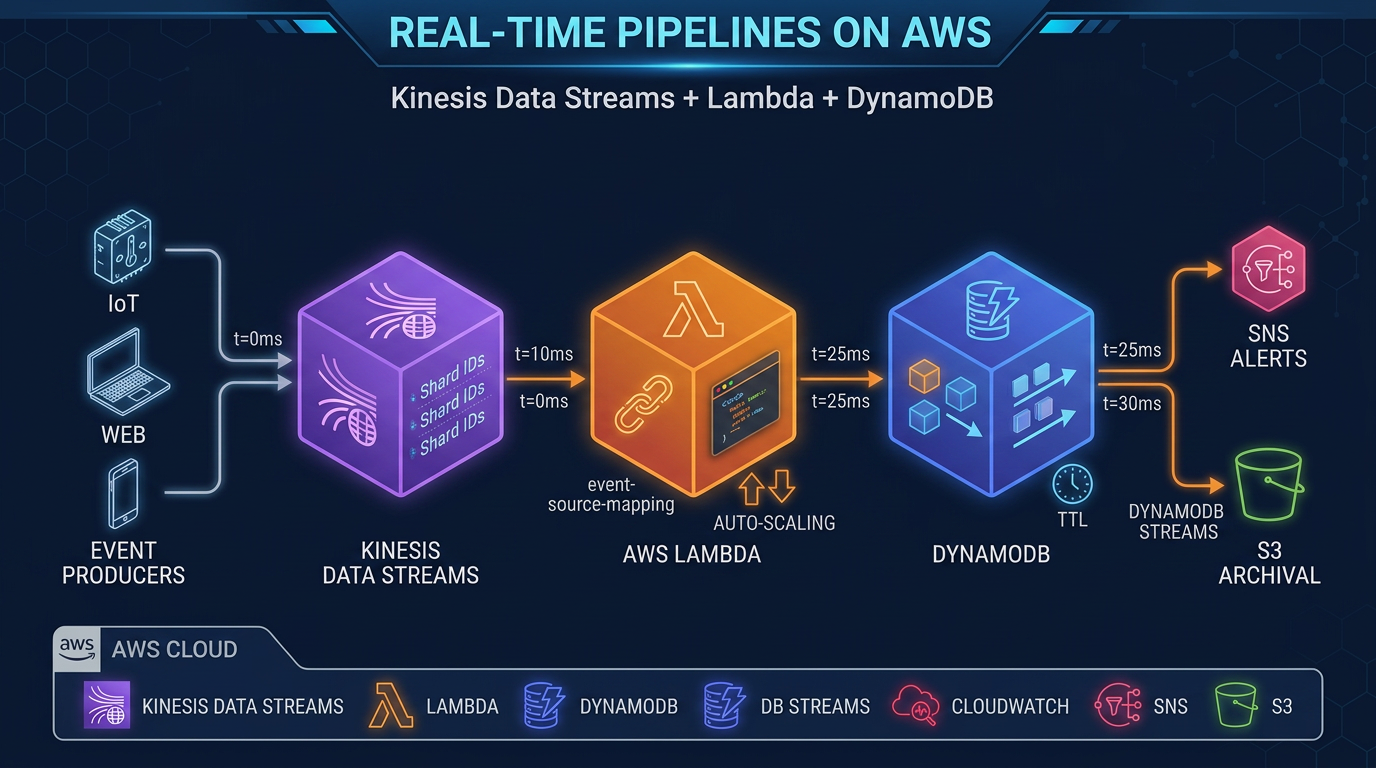
Benchmark pattern (not a cited client) — Composite order-ingest platform, ~8k TPS peak with per-customer ordering, ~1 KB payloads, us-east-1, three downstream consumers (fraud scoring, fulfillment, analytics). Phase 1 used SQS FIFO without high-throughput mode — effective ceiling ~300 TPS/API action, backlog age peaked ~14 min, modeled FIFO line ~$95/mo plus on-call time. Phase 2 enabled high-throughput FIFO with 50 message groups — same business TPS, backlog age < 30 s, modeled line ~$118/mo. Phase 3 (analytics-only fork) moved firehose-style telemetry to Kinesis on-demand at ~25k events/s — modeled ~$890/mo ingest/retrieval vs mis-sized MSK provisioned “for jobs” at ~$1,100/mo on the CSV failure row.
The four-tier ladder
| Tier | Throughput shape | You buy | You do not get |
|---|---|---|---|
| SQS Standard | Nearly unlimited horizontal scale | Per-request $, polling discipline | Global order, stream replay |
| SQS FIFO | 300 TPS/API → 3k batched → 70k high-throughput | Per-group ordering | Single-lane groups at peak |
| Kinesis Data Streams | Shard or on-demand MB/s | Retention, Lambda ESM, 50 EFO consumers | Kafka wire protocol |
| MSK | Partition + broker hours | Kafka Connect, consumer groups, compacted topics | Zero broker thinking |
| Flink (on Kinesis/MSK) | Stateful parallelism | Windows, joins, CEP | Simple queue semantics |
Opinionated take: Default SQS Standard for work queues; Kinesis on-demand for AWS-native multi-consumer streams; MSK only with dated Kafka requirements; Flink only when stateful stream SQL/joins are the product. Escalate tier when a documented ceiling bites — not when a resume mentions Kafka.
Tier 1 — SQS: request economics beat broker hours
AWS documents nearly unlimited throughput on SQS Standard queues. Your ceiling is almost always consumer count × handler duration × idempotency, not SQS itself.
FIFO is different. Without high-throughput mode, plan around 300 transactions per second per API action batch (async messaging boundaries — May 2026 refresh). Batching raises practical throughput; high-throughput FIFO mode targets up to ~70,000 TPS with explicit opt-in and per-message-group parallelism.
| Mistake | Symptom | Fix |
|---|---|---|
| Single FIFO message group | One lane at peak | Shard groups by customer_id, order_id, etc. |
| Short polling on idle queues | Empty-receive bill | WaitTimeSeconds=20 — see SQS pricing |
| 200 KB bodies | 4× request chunks | S3 pointer pattern |
What broke — Black Friday prep for a retail order pipeline. Ops raised FIFO
maxReceiveCountbut not throughput mode.ApproximateAgeOfOldestMessagehit ~22 min while CloudWatchNumberOfMessagesSentplateaued near ~280/s. Producers reported “no errors.” Detection: backlog age alarm + CSV failure rowsqs_fifo_wrong_tier. Fix: high-throughput FIFO + 40 message groups; fraud lane stayed FIFO, analytics fork moved to Kinesis the following sprint.
Tier 2 — Kinesis: MB/s, shards, and fan-out
Provisioned mode (per shard): 1 MB/s write, 2 MB/s read for standard consumers. On-demand mode scales shards automatically — ideal for variable ingest if you model retrieval and fan-out.
Enhanced fan-out (EFO): each registered consumer gets 2 MB/s dedicated read — critical when >5 services read the same stream. AWS increased the per-stream EFO consumer maximum to 50 (November 2025). Standard consumers still share shard read — adding Lambdas does not add read bandwidth.
October 2025 also raised max record size to 10 MiB — fewer chunking hacks for fat events.
Context — AWS CLI 2.x, read-only inventory:
# List streams and mode (on-demand vs provisioned)
aws kinesis list-streams --region us-east-1
aws kinesis describe-stream-summary --stream-name ORDER_EVENTS --region us-east-1Tier 3 — MSK: when Kafka protocol is non-negotiable
Choose MSK when you need Kafka consumer groups, Kafka Connect, compacted topics, or existing clients without rewrite.
| Mode | Ceiling (documented) | Fit |
|---|---|---|
| MSK Serverless | ~200 MBps write, ~400 MBps read per cluster | Bursty Kafka without cluster sizing |
| MSK provisioned | Broker-type dependent | Sustained >500 MB/s with RIs |
Do not provision three kafka.m5.large brokers to move 2k job messages/s — the CSV wrong_tier_kafka_for_jobs row models ~$1,100/mo vs ~$18/mo SQS for the same shape.
Tier 4 — Flink: compute layer, not queue replacement
Managed Service for Apache Flink belongs when you need session windows, stream joins, or CEP atop Kinesis or MSK. Transport stays on the log; Flink holds state and checkpoints.
Skip Flink when Lambda + DynamoDB + Step Functions already meet latency — you are buying checkpoint operations and key-group skew debugging.
Consumer parallelism cheat sheet
| Transport | Scale reads by | Anti-pattern |
|---|---|---|
| SQS Standard | More workers | Assuming exactly-once |
| SQS FIFO | More message group IDs | One group for all traffic |
| Kinesis | Shards + EFO consumers | 20 Lambdas on standard consumers |
| MSK | Partitions × group members | Rebalance during peak deploy |
| Flink | Parallelism / slots | Hot key in keyBy |
What to do this week
- Write peak TPS, payload KB, and ordering scope on one page.
- Run the decision matrix — if Kafka is not in the answer column, stop.
- Plug numbers into the cost CSV including the wrong-tier rows.
- For FIFO, confirm high-throughput mode and message-group spread before peak season.
- For Kinesis multi-team reads, model EFO cost vs shared-consumer lag.
What this post doesn’t cover
- Amazon MQ / RabbitMQ — see event-driven boundaries.
- EventBridge Pipes pricing — see EventBridge pricing.
- IoT MQTT ingest — see IoT Core MQTT.
- Exactly-once end-to-end proofs — see Kafka partition rebalancing.
Related: Architecture review · SQS pricing calculator · Kinesis vs MSK
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.