What Does an AWS Managed Services Partner Actually Do? (And What They Don't)
Quick summary: Most AWS MSP descriptions are vague. Here is a concrete breakdown of what a managed services partner actually does day-to-day — and what falls outside their scope.
Key Takeaways
- Most AWS MSP descriptions are vague
- The marketing language around AWS Managed Services Partners is reliably vague
- 24/7 support
- This post is a concrete breakdown of what a legitimate AWS MSP does, how they do it, and — equally important — what falls clearly outside the scope of a standard managed services engagement
- What an AWS MSP Does 1
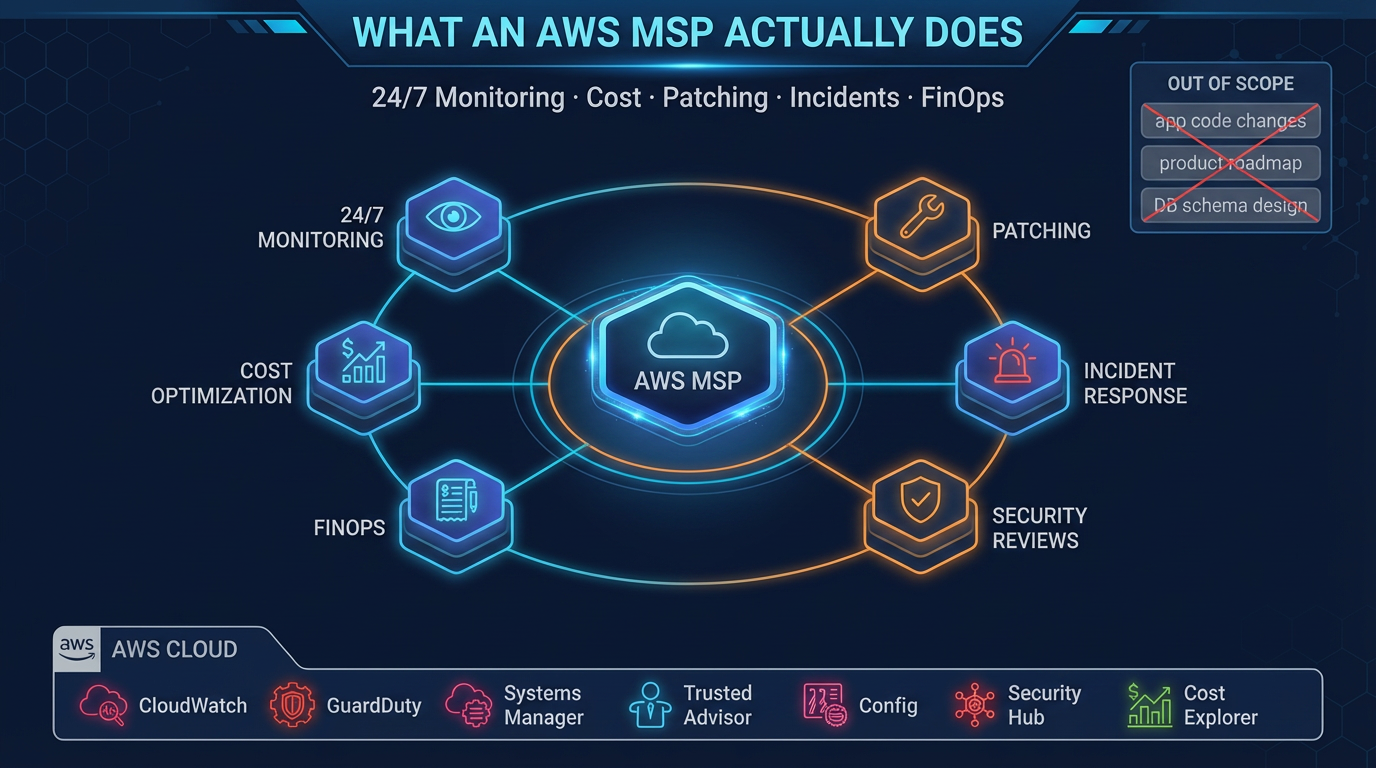
Table of Contents
The marketing language around AWS Managed Services Partners is reliably vague. “End-to-end cloud management.” “24/7 support.” “Cost optimization.” These phrases are in almost every MSP’s pitch, but they tell you almost nothing about what the engagement actually looks like day-to-day.
This post is a concrete breakdown of what a legitimate AWS MSP does, how they do it, and — equally important — what falls clearly outside the scope of a standard managed services engagement. If you are evaluating MSPs, this is the framework you need to ask the right questions.
What an AWS MSP Does
1. Continuous Monitoring and Alerting
This is the operational foundation of managed services. An MSP instruments your AWS environment with monitoring that watches infrastructure health 24 hours a day, 7 days a week, including nights, weekends, and holidays.
What this looks like in practice:
- CloudWatch alarms covering CPU utilization, memory (via CloudWatch Agent), disk space, RDS connection pool saturation, Lambda error rates, ECS task health, and ALB 5xx error rates
- Custom composite alarms that aggregate signals to reduce noise — for example, alerting on high CPU combined with elevated response latency rather than CPU alone
- Log-based alerting using CloudWatch Logs metric filters or a log aggregation platform (Datadog, Grafana Loki, Elasticsearch) that detects application error patterns, security events, and cost anomalies
- Threshold tuning based on your application’s actual behavior — not generic defaults — so alerts fire on meaningful deviations, not normal variance
The alert thresholds that a production-grade MSP monitors:
- EC2/ECS: CPU >80% sustained for 5 minutes, memory >85%, disk >80%
- RDS: Connection count >80% of max_connections, read latency >20ms (adjust for workload type), freeable memory <200MB
- Lambda: Error rate >1%, throttling >0.5%, duration approaching timeout within 20%
- ALB: 5xx rate >0.5% of requests, target response time >2s at p95
A human engineer reviews every P1 and P2 alert and takes action. Alerts do not just go to a dashboard — they produce a response.
2. Incident Response
When a production alarm fires at 2 AM, an MSP engineer wakes up. Not your engineer — theirs.
Incident response covers:
- Acknowledging alerts within the SLA window (typically 15 minutes for P1)
- Running predefined runbooks for known failure modes (RDS failover, EC2 instance recovery, ECS task restart, Lambda concurrency exhaustion)
- Escalating to your team when the incident requires business context or code changes
- Communicating status updates on a defined cadence during active incidents
- Documenting the timeline, root cause, and resolution steps in a post-incident report
What incident response does not cover is rebuilding your application or making decisions that require understanding your business logic. An MSP can restart a crashed ECS service, identify that a database query is causing the issue, and notify your team. Writing the query fix is your team’s job.
3. Cost Optimization (Ongoing, Not One-Time)
Cost optimization in a managed services engagement is a continuous process, not a one-time audit. The MSP monitors spend continuously and takes defined actions as part of standard operations.
Ongoing cost optimization activities:
- Monthly Cost Explorer review: Line-by-line analysis of spend changes, with attribution to specific workloads or events. If your bill increased $4,000 last month, the review identifies why.
- Rightsizing: Analyzing EC2, RDS, and ElastiCache utilization patterns over 30–90 days and recommending instance type or size changes where resources are consistently over-provisioned.
- Reserved Instances and Savings Plans: Analyzing your on-demand spend baseline and recommending 1-year or 3-year commitment purchases. An MSP tracks your commitment coverage and recommends top-ups as workloads grow.
- Idle resource cleanup: Identifying and flagging (or removing, with approval) unattached EBS volumes, unused Elastic IPs, stopped EC2 instances, empty S3 buckets with storage costs, and orphaned load balancers.
- Data transfer optimization: Identifying architecture patterns that generate unnecessary cross-region or cross-AZ data transfer charges.
- Tagging governance: Implementing and enforcing a tagging policy so every resource is attributable to a cost center, team, and environment. This is a prerequisite for meaningful cost attribution.
A realistic expectation: a well-run MSP engagement produces 15–25% cost reduction within the first 90 days, and then ongoing savings of 5–10% annually compared to unmanaged spend.
4. Patch Management
An MSP implements a structured patching cadence that keeps your EC2 instances and managed service configurations current on security patches.
The patching process:
- Security patches are evaluated against your environment within 30 days of release (often 14 days for critical patches)
- AWS Systems Manager Patch Manager is configured with a baseline specifying which patches apply automatically versus require approval
- Maintenance windows are scheduled during low-traffic periods (typically early Sunday morning)
- Pre-patch AMI snapshots or EBS snapshots provide rollback capability
- Post-patch health checks verify application functionality before the maintenance window closes
- Patch compliance reports are generated monthly for audit purposes
Patching covers OS-level packages (the operating system and system libraries). Application dependencies — your Python packages, npm modules, Ruby gems, Java libraries — are your team’s responsibility.
5. Security Reviews and Compliance Monitoring
An MSP runs continuous security monitoring and scheduled reviews that keep your security posture current.
Continuous security monitoring:
- AWS GuardDuty findings reviewed and triaged — P1 findings (root credential usage, crypto mining indicators, unusual data exfiltration) produce immediate alerts
- AWS Security Hub aggregates findings from GuardDuty, Config, Inspector, and IAM Access Analyzer into a single view
- CloudTrail audit logs preserved and monitored for anomalous API call patterns (calls from unusual IP addresses, mass deletion events, IAM privilege escalation)
- AWS Config rules enforce configuration compliance — public S3 buckets, unencrypted EBS volumes, security groups with broad ingress rules
Scheduled security reviews:
- Quarterly IAM access reviews: identifying unused IAM users, access keys older than 90 days, roles with excessive permissions
- Monthly review of AWS Config compliance score
- Annual penetration testing coordination (MSPs typically coordinate, not conduct — pen testing is a separate engagement)
- Compliance evidence generation for SOC 2, HIPAA, or PCI frameworks as applicable
6. Infrastructure Documentation and Runbook Maintenance
Operational knowledge should not live in an individual’s head. An MSP maintains current documentation of your environment as part of standard operations.
What should be documented:
- Architecture diagrams at account, VPC, and service level
- Runbooks for every repeated operational task (deployments, incident response, DR drills, patching)
- Change history and the rationale for significant infrastructure decisions
- Dependency maps between services
- Cost attribution model and tagging conventions
This documentation is yours. A responsible MSP ensures you have access to it and could transition to a different provider or in-house team with it.
What an AWS MSP Does Not Do
Being explicit about scope prevents misaligned expectations. These items are commonly assumed to be part of managed services, but are not.
Application Code and Business Logic
An MSP manages AWS infrastructure, not your application. They can tell you that your Lambda function is timing out, identify that the timeout correlates with a specific input pattern, and notify your team. Writing the code fix is your team’s job. MSPs do not modify application code, refactor database queries, or make product decisions.
New Feature Development
Managed services covers the operational lifecycle of existing infrastructure. Designing and building new infrastructure for new product features is typically a project engagement, not part of an ongoing operations contract. Some MSPs offer project services alongside managed operations, but these are scoped and priced separately.
Data Science and Machine Learning Pipelines
Unless specifically contracted, data pipeline management, ML model training schedules, feature stores, and data warehouse maintenance fall outside standard managed services. Some MSPs have specialized data engineering practices — ask explicitly if this is a requirement.
Third-Party SaaS and External Dependencies
An MSP monitors your AWS resources. If your application depends on Stripe, Twilio, Datadog, or any other third-party SaaS, their availability and performance are outside the MSP’s management scope. They can detect that your application is failing because an external dependency is unreachable, but they cannot fix the external service.
Product Roadmap and Architecture Strategy
Day-to-day operations and strategic architecture decisions are different things. An MSP can advise on AWS service choices and flag architectural concerns, but they do not own your architecture direction. Major architectural decisions — migrating from EC2 to containers, adopting serverless for a new service tier, evaluating a new data warehouse — should be driven by your team with input from qualified advisors.
Business Continuity Beyond Infrastructure
An MSP manages infrastructure-level disaster recovery: RDS backups, cross-region replication, failover procedures. They do not own your business continuity plan, which includes people, processes, communication plans, and recovery priorities that extend beyond the infrastructure layer.
How to Verify an MSP’s Claims
When evaluating an MSP, go beyond their marketing material. Ask for specifics:
- What monitoring platform do you use, and will we have direct access to the dashboards?
- Show me an example post-incident report from a recent engagement.
- What is your on-call schedule structure? How many engineers are on-call on a given night?
- What does your patching runbook look like for an EC2 fleet?
- How do you handle a situation where a patch causes an application regression?
- What is included in your monthly cost optimization review, and what does a typical report look like?
MSPs who have operational discipline will answer these questions with specificity. Those who respond with generalities are telling you something important about how they operate.
Making the Decision
The clearest sign that an MSP is the right investment: your engineering team is spending meaningful time on cloud operations work that is not advancing your product, and the cost of that diverted attention exceeds what an MSP charges.
The clearest sign it is premature: your infrastructure is simple, your team has the expertise and bandwidth to manage it, and the additional coordination overhead of an external partner would slow you down.
For companies in the middle — past simple but not yet at scale-out — managed services is often the right bridge. It buys operational maturity without requiring you to build a platform engineering team before you are ready.
FactualMinds provides AWS Managed Services with transparent scope, defined SLAs, and no lock-in through proprietary tooling. If you want to discuss whether managed services is the right fit for your environment, reach out directly.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.