AWS RDS Performance and Caching: IOPS, Query Tuning, and Application-Layer Cache Patterns
Quick summary: A production-focused guide to Amazon RDS performance: EBS gp3 IOPS and throughput, Performance Insights, read replicas, RDS Proxy, and aggressive application caching with ElastiCache—without outdated patterns like MySQL query cache.
Key Takeaways
- Implementation detail is RDS-specific and checked against how RDS and EBS behave today
- If you are still deciding between RDS and Aurora, start with RDS vs Aurora: when to use which—then return here for operational tuning
- Shipping a performance initiative on RDS
- AWS RDS consulting or contact us
- 1
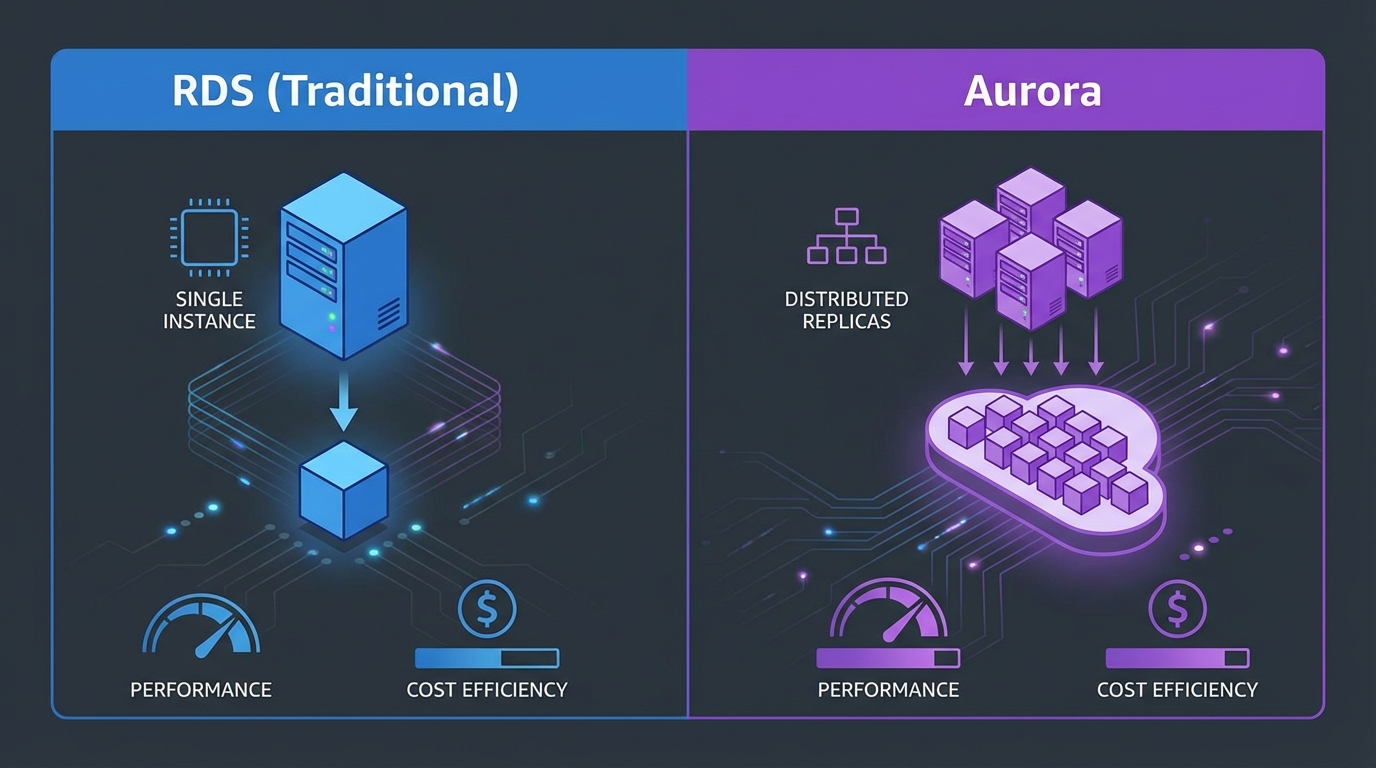
Table of Contents
Database performance advice often ages badly: storage classes change, engines drop features, and “turn on the query cache”-style tips become harmful. This guide covers the durable fundamentals — indexing, query plans, pooling, replication, monitoring — translated onto Amazon RDS with current AWS primitives: gp3 IOPS, Performance Insights, RDS Proxy, read replicas, and application-side caching (ElastiCache / layered caches). Implementation detail is RDS-specific and checked against how RDS and EBS behave today.
If you are still deciding between RDS and Aurora, start with RDS vs Aurora: when to use which—then return here for operational tuning.
Shipping a performance initiative on RDS? FactualMinds helps teams baseline with Performance Insights, right-size storage and instances, and design cache-and-replica topologies that stay secure and cost-aware. AWS RDS consulting or contact us.
1. Start with evidence: Performance Insights and CloudWatch
Guessing whether you are I/O-bound, CPU-bound, or lock-bound leads to expensive mis-provisioning.
- Performance Insights surfaces DB load and top SQL and wait events (I/O, CPU, locks, latch contention—engine-dependent). Use it to answer: “Is the database waiting on storage, or executing?”
- CloudWatch metrics such as
ReadLatency,WriteLatency,DiskQueueDepth,DatabaseConnections, andFreeableMemorycomplement PI. Spikes in queue depth with flat CPU often point to storage throughput or IOPS limits. - Enhanced Monitoring (optional) adds OS-level granularity—useful when you suspect filesystem buffer pressure or niche kernel-level symptoms.
Practice: snapshot a one-week baseline before changing instance class or storage. Optimize top queries first when PI shows CPU and lock waits, not I/O saturation.
2. Indexing and schema design on RDS
Indexes speed selective reads but add write amplification—every secondary index must be maintained on insert/update/delete.
- Review quarterly: unused indexes (PostgreSQL:
pg_stat_user_indexes; MySQL: information schema / performance_schema patterns) and missing indexes driving sequential scans or full table scans on large tables. - Composite indexes: match equality predicates first, then range columns; avoid wide index payloads you do not query.
- Normalization vs denormalization: third normal form keeps correctness and smaller writes; controlled denormalization (summary columns, materialized aggregates) can cut read I/O for dashboards—trade redundant writes and consistency rules for speed.
RDS does not remove the need for good schema hygiene; Multi-AZ and read replicas do not fix a missing index on a growing table.
3. Query optimization (engine-aware)
Cross-engine principles:
- Prefer explicit column lists over
SELECT *in hot paths—less I/O and fewer wide-row surprises when the schema evolves. - Use
EXPLAIN(and on PostgreSQL,EXPLAIN (ANALYZE, BUFFERS)in non-production or with caution) to verify plans: index usage, estimated vs actual rows, buffer hits. - Keep predicates sargable—functions on indexed columns often defeat indexes (
WHERE LOWER(email) = ...vs storing a normalized column).
PostgreSQL on RDS: watch bloat and autovacuum health; long-running transactions block vacuum and inflate dead tuples. MySQL/InnoDB: align buffer pool expectations with instance memory (larger instances cache more hot pages in memory, reducing read I/O).
4. AWS storage and IOPS: gp3-first, then provisioned IOPS when justified
RDS data volumes on Amazon EBS are where many teams overspend or under-provision.
gp3 (default recommendation for new deployments)
- gp3 provides a baseline of 3000 IOPS and 125 MiB/s throughput (standard configuration) and lets you increase IOPS and throughput independently of allocated volume size—up to limits imposed by RDS for your engine and instance class.
- This is a major upgrade over older “IOPS scales mostly with volume size” mental models tied to gp2.
Practices:
- If PI and
DiskQueueDepthshow queuing with low CPU, raise provisioned IOPS or throughput on gp3 before jumping to a larger instance class. - Avoid tiny volumes with aggressive burst expectations; size storage for data growth and enable storage autoscaling with sensible maximum caps so autoscaling cannot run away unnoticed.
- Align checkpoint and write-heavy batch jobs with storage capability—sudden bursts can stress throughput even when average IOPS looks comfortable.
io1 / io2 Block Express
Use provisioned IOPS (PIOPS) storage when you have proved with metrics that gp3 at your tier cannot deliver the sustained latency profile you need—low variance read/write latency at very high IOPS. Cost is higher; treat it as a targeted fix, not a default.
What we are not recommending
- Do not default to gp2 for new designs unless you have a legacy constraint; prefer gp3 for predictable baselines.
- Do not confuse RDS Multi-AZ (availability) with read scaling—the standby is not a query replica.
Aurora note
Amazon Aurora uses a different storage and I/O billing model and offers I/O-Optimized for I/O-heavy clusters. If I/O cost dominates on Aurora, compare I/O-Optimized against standard—details in RDS vs Aurora.
5. Connection management and RDS Proxy
Opening a TLS connection to PostgreSQL or MySQL is expensive compared to executing a simple statement. At scale, connection churn wastes CPU on the database and can hit max_connections.
- Application pools (HikariCP, SQLAlchemy pools, etc.) are mandatory in long-lived services.
- Amazon RDS Proxy sits between apps and RDS/Aurora: it multiplexes application connections to a bounded pool of database connections, improves behavior under failover, and supports IAM database authentication for many setups.
Lambda and bursty Kubernetes: Proxy is often the difference between steady-state and too many connections incidents. It is not a substitute for fixing slow SQL.
6. Read replicas: scale reads without pretending lag does not exist
RDS read replicas offload read traffic from the primary. They are appropriate for reporting, eventually consistent read paths, and horizontally scaled read workers.
Pitfalls:
- Replication lag: a user writes on the primary and immediately hits a replica—they may not see their write. Route session-bound reads to the primary or use read-after-write awareness in the app.
- Duplicate work: adding replicas without fixing queries only spreads inefficient SQL across more CPUs.
Use PI on the primary to eliminate the worst offenders before linearly scaling replicas.
7. Caching: long-lived, hot-query, and aggressive application layers
RDS has no MySQL 8.0 query cache. Modern systems cache outside the core engine (and sometimes in application memory) with explicit TTL and invalidation discipline.
7.1 Long cache for data that rarely changes
For reference data, config blobs, feature flags, or stable aggregates:
- Use long TTLs with a version key or content hash in the cache key so bulk invalidation is a single
DELor namespace bump—not thousands of fragile keys. - Stale-while-revalidate: return slightly stale payload instantly while one async path rebuilds—better user latency than blocking on cold cache.
- Never rely on infinite TTL without a story for admin edits—pair long TTL with pub/sub invalidation (Redis channels) or event-driven invalidation on writes.
7.2 Cache frequently accessed (“hot”) queries
- Identify candidates from Performance Insights top SQL and slow query logs—expensive, stable reads with high cardinality of callers but parameterized shapes.
- Key design: include bounded parameters; avoid exploding keyspaces (e.g., caching every arbitrary
LIMITvalue). - Stampede control: jittered TTLs, single-flight refresh, short “in-flight” locks.
7.3 Aggressive application caching (layered)
A practical production stack:
- In-process cache (seconds to minutes) for ultra-hot, read-only slices—bounded size, no unbounded map growth.
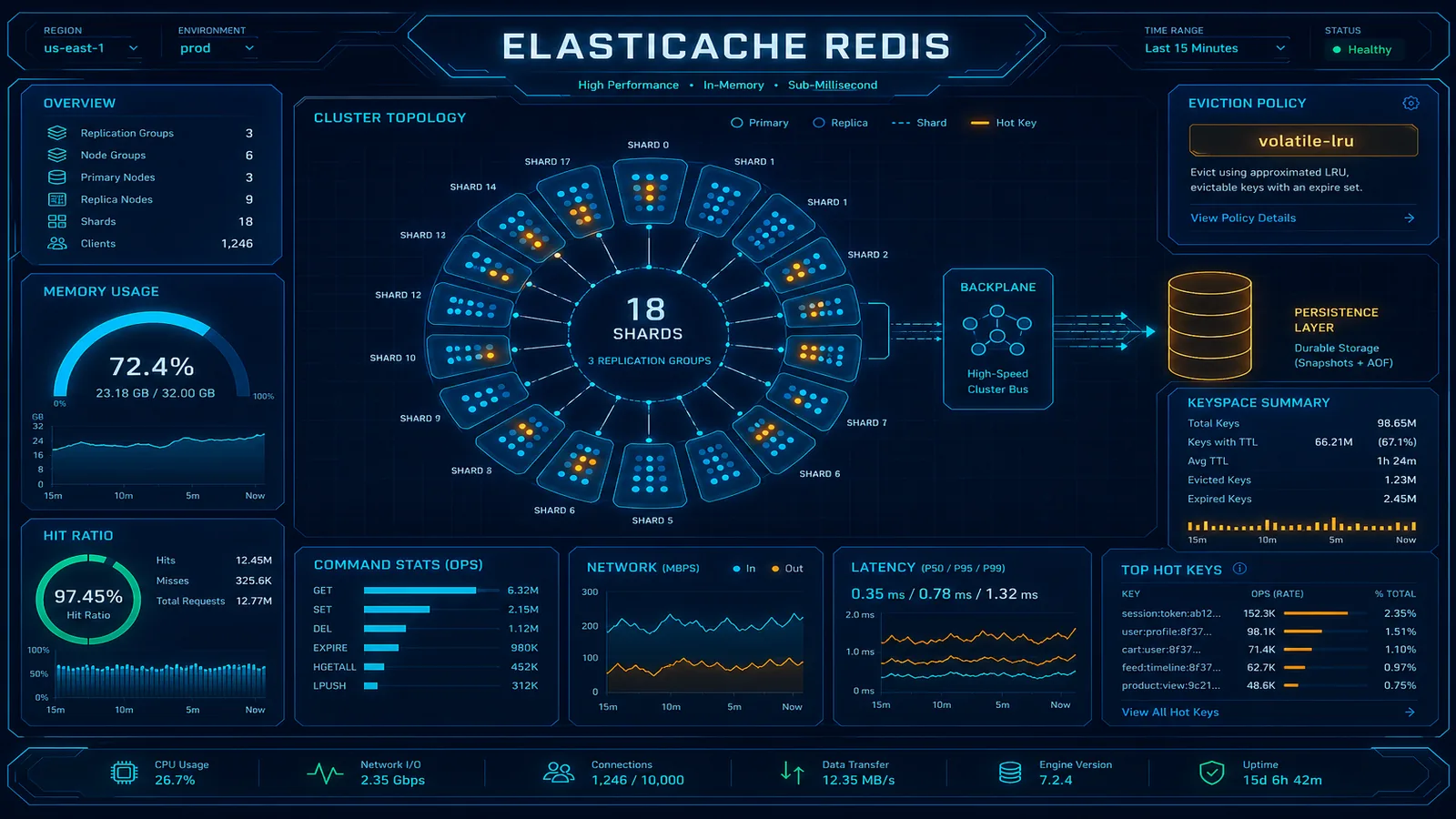
- Shared remote cache—Amazon ElastiCache (Redis or Memcached) for cross-instance consistency and larger working sets. For Redis-specific patterns, see ElastiCache caching strategies in production.
- Negative caching for known misses (short TTL) to protect the database from repeated “not found” storms.
Bulkheads: cap concurrent cache refresh tasks; shed load rather than taking the database with you.
Observability: export hit rate, latency, evictions, and errors from your cache client—the same way you monitor RDS PI.
Note: Amazon DynamoDB accelerators like DAX apply to DynamoDB, not RDS—different product line.
8. Monitoring checklist (condensed)
| Signal | Indicates |
|---|---|
| High DB Load + I/O wait in PI | Storage IOPS/throughput or disk subsystem pressure |
| High CPU + CPU wait | Query inefficiency, missing indexes, or too much connection overhead |
| Rising DatabaseConnections | Pool misconfiguration, missing Proxy, or connection leaks |
| FreeableMemory collapse | Working set larger than RAM; consider class size or query/I/O reduction |
| Replica lag metrics | Stretched replication—throttle heavy writes or improve network/instance balance |
9. Security and compliance touchpoints (brief)
Performance work intersects security:
- Encryption at rest (KMS) and in transit (TLS to RDS) remain non-negotiable for regulated workloads.
- IAM database authentication changes how credentials rotate—ensure pools and Proxy settings align with your identity pattern.
- Auditors care about data lineage for caches: do not cache sensitive fields wider than necessary; set TTLs consistent with policy.
Related reading
- RDS vs Aurora: when to use which
- ElastiCache Redis caching strategies
- High-scale Postgres on AWS without breaking the bank — RDS Proxy vs PgBouncer, BRIN indexes, and the cost/performance trade-offs that complement the tuning patterns above.
Service limits, pricing, and engine defaults change — validate storage and instance maximums in the current Amazon RDS documentation before large purchases.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.