Virtual Data Modeling on AWS: Architecture, Trade-offs, and When Not to Use It
Quick summary: Virtual data modeling on AWS: Athena/Redshift semantic views without copies. July 2026 — when VDM works, when it burns Athena dollars.
Key Takeaways
- Virtual data modeling on AWS: Athena/Redshift semantic views without copies
- July 2026 — when VDM works, when it burns Athena dollars
- First-party benchmark (illustrative): a mid-market retailer with ~5–20 TB curated Parquet often cuts “which dataset is truth
- Without them, VDM becomes a scan amplifier at ~$5/TB (re-quote Athena pricing)
- Reproduce this: VDM zone decision matrix Counter-case: sub-100ms product APIs and write-heavy OLTP do not belong behind Athena/Spectrum views — use purpose-built stores
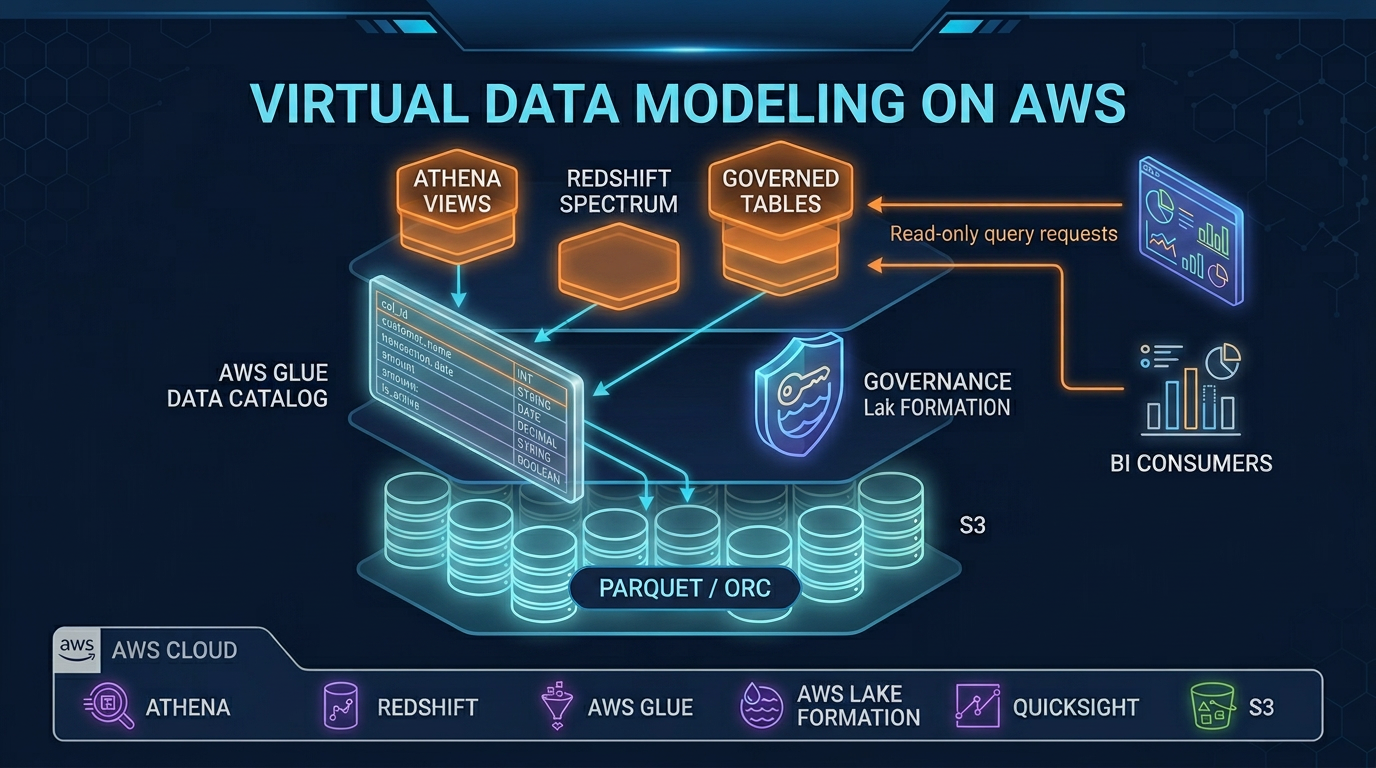
Table of Contents
Most data teams still solve “one more BI question” with one more ETL table. Two years later you have twenty versions of “orders with customer info,” and finance vs product both win — on different tables. As of July 2026, the structural fix on AWS is still a read-only virtual data model: Athena/Glue views, Redshift late-binding views / Spectrum / data sharing, and Lake Formation governance over curated Parquet (or Iceberg) — without copying the lake for every consumer.
First-party benchmark (illustrative): a mid-market retailer with ~5–20 TB curated Parquet often cuts “which dataset is truth?” thrash after publishing a small sem_* zone — but only if partitions and Athena workgroup scan limits exist. Without them, VDM becomes a scan amplifier at ~$5/TB (re-quote Athena pricing).
Reproduce this: VDM zone decision matrix
Counter-case: sub-100ms product APIs and write-heavy OLTP do not belong behind Athena/Spectrum views — use purpose-built stores.
This guide covers what VDM is, AWS building blocks, and when not to use it.
What Virtual Data Modeling Is (and Is Not)
A virtual data model is a collection of named logical definitions — SQL views, governed table definitions, or named query templates — that sit between physical storage and data consumers. The model defines business entities (a “Customer”, an “Order”, a “Campaign”) in terms of underlying physical tables, without creating a new physical copy of the data.
The three-tier structure common in AWS data architectures maps naturally:
- Raw zone — Data as-landed from source systems. Partitioned by ingestion date or source. No transformations. Direct consumer access is typically blocked.
- Curated zone — Cleaned, deduplicated, type-cast data in Parquet format. Still represents source entities (orders, events, users) without applying business logic.
- Semantic zone — The virtual data model. Business-defined entities with business logic applied:
net_revenueinstead ofamount - discount_amount,active_customeras a derived flag,campaign_attributed_ordersjoining three physical tables with agreed attribution logic.
Important: A virtual data model is strictly a read-only abstraction. When a consumer queries a VDM view, the query engine reads from physical storage, applies transformations in memory, and returns results. No data is written, mutated, or persisted. There is no equivalent to
INSERT,UPDATE, orDELETEoperating through a virtual layer. This is both the strength and the constraint of the pattern: the model cannot accumulate state, cannot cache transformations, and cannot act as a write target for downstream systems.
Where VDM Fits in Modern Data Architectures
| Architecture | Physical Layer | VDM Layer Position | Typical AWS Implementation |
|---|---|---|---|
| Data Lake | S3 (raw + curated Parquet) | Above curated, below BI | Athena views + Lake Formation |
| Lakehouse | S3 + Iceberg/Delta tables | Semantic zone views | Athena or Glue + Redshift Spectrum |
| Cloud Warehouse | Redshift provisioned/serverless | Late-binding views, data sharing | Redshift views + Redshift Spectrum |
| Hybrid (Lake + Warehouse) | S3 raw + Redshift curated | Federated views spanning both | Redshift Spectrum + external schemas |
The VDM layer does not replace your warehouse or lake — it mediates access to both. BI tools, data science notebooks, and application queries point at the semantic layer; engineers control what business logic is canonical without touching consumer connection strings.
AWS Services That Implement the Virtual Layer
Amazon Athena Views
Athena views are the most lightweight VDM option. A view is a named SQL statement stored in the AWS Glue Data Catalog; querying it executes the underlying SQL against the physical S3-backed tables at read time. Views support joins across multiple Glue databases, partition filter pushdown, and standard SQL window functions.
The constraint: every query against an Athena view incurs Athena compute and data scanning charges. A complex view joining three 500 GB tables does not “pre-compute” anything — it re-executes the full join on every query. Partition pruning and columnar formats are not optional; they are the primary cost control mechanism.
Amazon Redshift Late-Binding Views and Data Sharing
Late-binding views in Redshift defer schema resolution to query time, which means views survive underlying table schema changes without recompilation — a meaningful operational advantage over standard views in large, evolving schemas.
Redshift data sharing allows producer clusters to expose named databases (a logical VDM) to consumer clusters or Redshift Serverless namespaces without data movement. Consumers query live, producer-side data through the share; data never leaves the producer storage. This is the closest AWS-native equivalent to true data virtualization at the warehouse tier.
Redshift Spectrum extends views to S3-backed external tables, enabling semantic views that join Redshift-resident data with S3 data lake content — the most common pattern in hybrid architectures.
AWS Glue Data Catalog
The Glue Data Catalog is the metadata backbone: it stores table definitions, partition layouts, column types, and view SQL for both Athena and Redshift Spectrum. In a VDM architecture, the catalog is where the semantic layer lives — the view definitions, governed table names, and schema documentation that make the logical model navigable.
Glue Schema Registry adds schema versioning and compatibility enforcement (backward, forward, full), critical for preventing schema drift from breaking consumer queries silently.
AWS Lake Formation
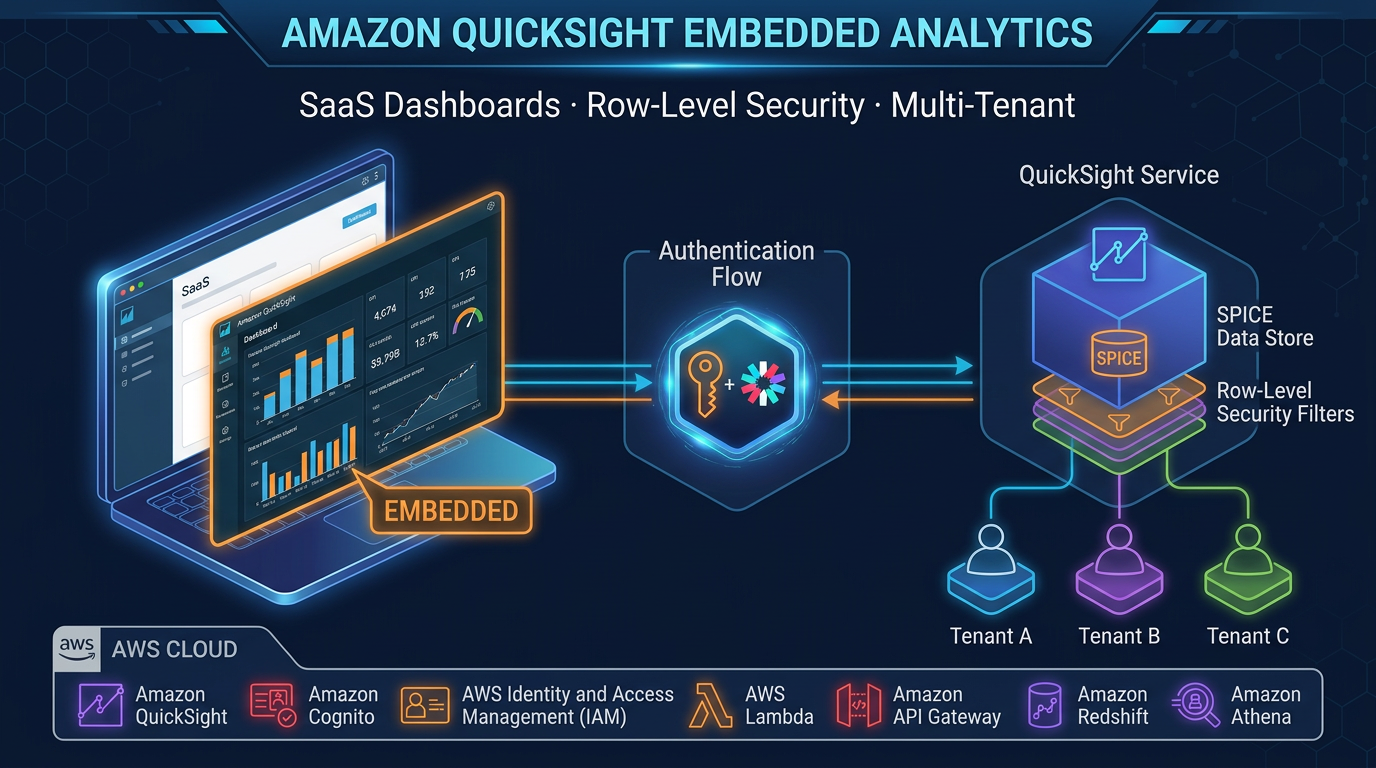
Lake Formation is the governance layer over the virtual model. It enforces column-level security (masking or restricting access to PII columns), row-level filters by user tag, and cross-account data sharing policies. In a VDM architecture, Lake Formation is what makes the semantic layer safe for broad internal access: engineers can publish the orders_semantic view to all analysts while ensuring that customer_email is masked for users outside the data privacy role.
When to Use Virtual Data Modeling
Multi-source data abstraction. When your semantic entities span sources — Salesforce CRM in S3, Redshift billing data, and RDS operational data — a VDM view with Redshift Spectrum or Athena federated queries provides a single logical table to consumers without ETL duplication.
Governed data access without data copies. Security-sensitive environments (HIPAA, PCI, SOC 2) benefit from VDM: instead of giving analysts access to raw tables containing PHI, expose a governed semantic view with masked columns and row-level filters via Lake Formation. The physical table is never directly accessible.
Simplifying BI tool dataset management. A well-designed VDM semantic layer reduces the number of datasets in QuickSight, Tableau, or Power BI from dozens to a handful of authoritative entities. This directly reduces the “which dataset is correct?” problem that plagues organizations with proliferating ETL pipelines.
Decoupling storage from consumers. When physical data formats change (migrating from Hive-partitioned CSVs to Iceberg Parquet), a VDM layer absorbs the change. Consumer query patterns remain stable while the underlying physical implementation evolves — engineers update the view definition, not every downstream query.
When Not to Use Virtual Data Modeling
Write-heavy or transactional workloads. A VDM layer is a query interface, not a write target. Operational applications that insert, update, or delete records need direct database access (RDS, DynamoDB, Aurora) — the virtual layer cannot substitute.
Sub-100ms latency requirements. Athena cold query startup adds 1–3 seconds of latency independent of data volume. Redshift queries over Spectrum add similar overhead for the S3 round-trip. If an application requires query responses under 100 milliseconds, the physical data source must be purpose-built for low-latency access (DynamoDB, ElastiCache, Aurora) — not abstracted through a virtual layer.
Transformation results that must persist. When downstream consumers need to build on top of transformed data — running aggregations over an aggregation, joining pre-aggregated entities — materializing transformations into physical tables (via Glue ETL or dbt) is almost always better than stacking views. Deep view hierarchies in Athena do not optimize; each nested view re-executes its full subquery.
Unpartitioned high-cardinality scans. A VDM view over an unpartitioned, 10 TB S3 table will scan 10 TB on every query. The virtual layer does not add the physical optimizations the data needs. Fix the storage layer first.
Best Practices for AWS Virtual Data Modeling
Enforce a naming convention. Views should be unambiguous about their zone and entity. A convention like raw_<source>_<entity>, curated_<entity>, sem_<domain>_<entity> prevents confusion. BI teams especially benefit from sem_ prefixed tables — they know they are querying canonical, governed definitions.
Align views with partition boundaries. Every semantic view should expose the underlying partition keys and document which columns trigger partition pruning. Consumers who do not know to filter on event_date will execute full-table scans. Include column comments in the Glue Data Catalog schema.
Use Lake Formation column masking for PII at the semantic layer. Do not implement PII controls in view SQL (CASE WHEN role = 'admin' THEN email ELSE NULL END) — it is fragile and bypasses Lake Formation’s audit logging. Apply Lake Formation data filters to the governed table; masking is enforced at the IAM/Lake Formation level regardless of how the view is written.
Test cross-account access with a minimal query before building. Cross-account Lake Formation resource links are the most common source of silent failures in VDM deployments. Validate that a SELECT 1 returns from the consumer account before constructing view hierarchies.
Cost Optimization
Athena charges $5 per terabyte scanned — a VDM layer that encourages broad, unfiltered queries will generate unexpected bills quickly. Three mandatory practices:
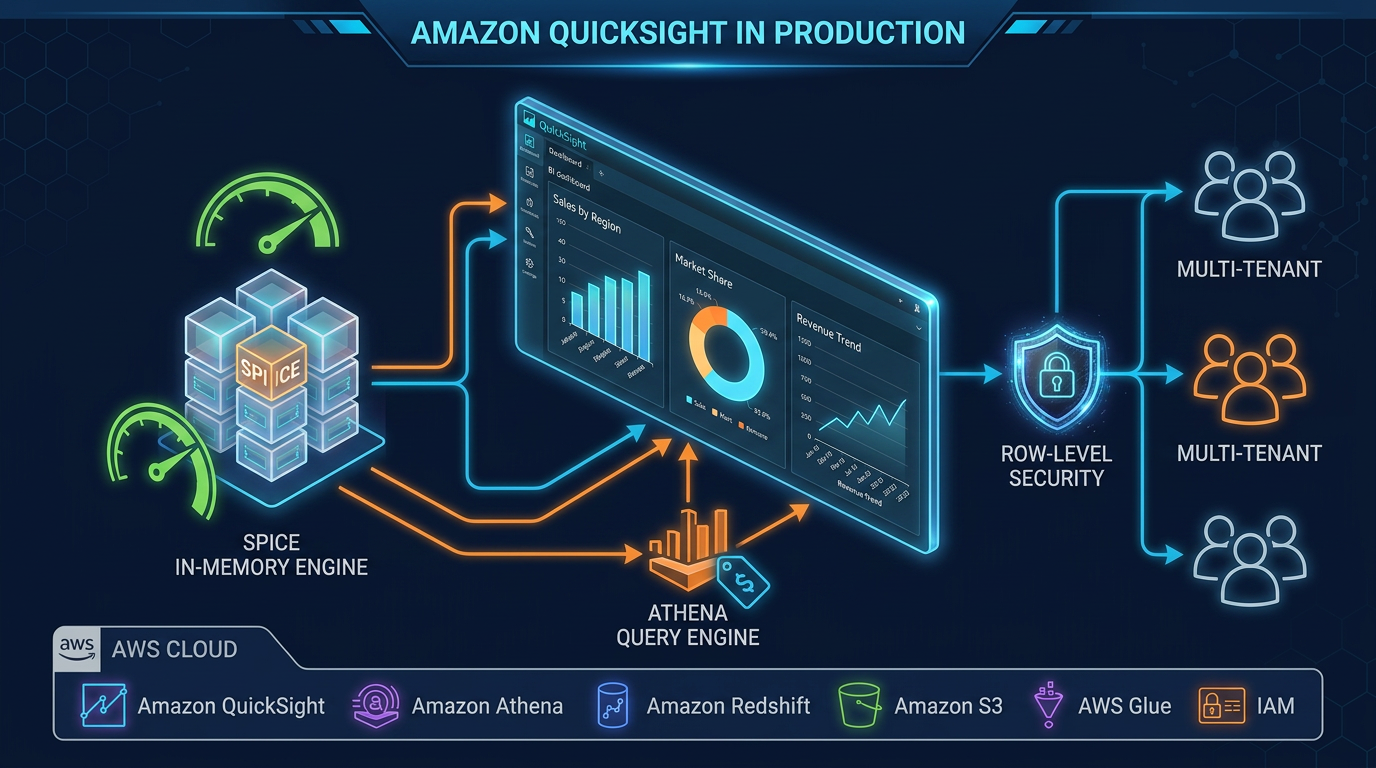
Columnar Parquet or ORC at the curated layer. Parquet with Snappy compression typically reduces Athena scan costs by 85–95% versus row-oriented formats. The VDM layer inherits this optimization automatically; views over Parquet tables scan far less data than views over CSV.
Partition filter pushdown. Write views that expose partition columns and document that filtering on them is required for performant queries. Use Athena workgroup settings to enforce per-query scan limits for consumer workgroups.
QuickSight SPICE for stable dashboards. For dashboard consumers with predictable, stable datasets, ingest VDM query results into QuickSight SPICE (Super-fast, Parallel, In-memory Calculation Engine) on a scheduled refresh. SPICE eliminates per-render Athena charges for the most frequent query patterns — a QuickSight dashboard with 100 daily viewers can eliminate thousands of Athena invocations per day.
For Redshift-backed VDM, Redshift Spectrum result caching reuses query results for identical queries within a configurable window. Combined with Redshift’s concurrency scaling, this handles bursty BI workloads without per-query data lake scan costs.
Streaming and Near Real-Time Trade-offs
A virtual data model over S3 delivers near-real-time data, not real-time data. The typical pattern — Amazon Data Firehose (formerly Kinesis Data Firehose) → S3 (Parquet, partitioned by event minute) → Athena view — achieves data freshness of 1–5 minutes, bounded by Firehose buffer intervals and Glue partition registration latency.
For dashboards where 5-minute lag is acceptable, this pattern is operationally simple and cost-effective. The VDM layer is unaware of streaming — it queries whatever files currently exist in S3.
For sub-minute freshness requirements, the VDM-over-S3 pattern breaks down. The right architecture is Redshift Streaming Ingestion from Kinesis Data Streams directly into Redshift materialized views, or Managed Service for Apache Flink writing to a purpose-built low-latency store. These are write-path solutions, not virtual layer solutions — the distinction matters for architecture decisions.
Edge Cases and Known Limitations
Schema drift. When a physical Parquet schema changes (a column type widened, a field renamed), downstream Athena views that reference the old column name return NULL or fail at query time without a clear error. Glue Schema Registry with BACKWARD_TRANSITIVE compatibility mode prevents incompatible changes from reaching the catalog; enforce it before you have a production incident.
Cross-account and cross-region complexity. AWS Lake Formation resource links support cross-account data sharing — see the secure cross-account data sharing guide for RAM + LF-Tag patterns — but cross-region data sharing requires Redshift data sharing or explicit S3 replication — there is no serverless cross-region Athena federation path. Organizations with strict data residency requirements must design region topology before building the virtual layer.
Complex join latency. Athena views joining five or more tables with complex predicate logic regularly produce queries exceeding 30–60 seconds for moderate data volumes. Profiling with EXPLAIN and pushing frequently-joined lookups into pre-materialized curated tables eliminates most of these bottlenecks — but it requires identifying them under load, not in development.
Designing for BI Consumers
The semantic zone is what QuickSight, Tableau, and Power BI authors see. A well-designed VDM layer means BI authors spend time building dashboards, not hunting for the correct table or reconciling conflicting column names.
Three conventions that reduce BI support overhead:
- Business-named columns:
total_net_revenue_usdnotamt_net_d. BI tools surface column names directly to end users. - Pre-joined entities: A
sem_orders_fullview that joins order headers, line items, and customer data eliminates the need for BI authors to know the physical join key. The view handles the join; the BI tool gets a flat, queryable entity. - Explicit NULL semantics: Document in column comments whether
NULLmeans “not applicable”, “not yet collected”, or “data not available”. BI dashboards that silently exclude NULLs from aggregates produce wrong numbers.
What to Do This Week
- Inventory consumer tables that are near-duplicates of “orders + customer.”
- Publish one
sem_*view over partitioned Parquet with Lake Formation grants — not twenty ETL copies. - Cap Athena workgroup scans; fill the decision matrix.
What This Post Doesn’t Cover
dbt Semantic Layer products, Tableau published data sources as the sole semantic store, and Snowflake-native modeling — different platforms, same discipline.
If you are designing a new lake semantic zone or collapsing ETL sprawl, AWS data analytics engagements cover zone design through Lake Formation rollout. Contact us.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.