· Palaniappan P · 11 min read
What DevOps Guides Don't Tell You About Production AWS
Most DevOps guides teach what AWS services are. Production teaches what happens when 200 engineers use them together. Here's the gap.
Most DevOps guides teach what AWS services are. Production teaches what happens when 200 engineers use them together. Here's the gap.
A security hardening PR in the AWS CLI applied chmod 0600 to any output path — including /dev/null — silently breaking Lambda invocations, S3 streaming commands, and every other process on affected hosts overnight.
LocalStack went paid. MiniStack and floci both stepped up as free, MIT-licensed AWS emulators. We reviewed both — their architecture, services, and performance — so you can pick the right one for your team.

Real AWS DevOps practices from production: GitOps on EKS, OpenTelemetry, supply chain security, chaos engineering with FIS, and AI-assisted DevOps with Amazon Q.
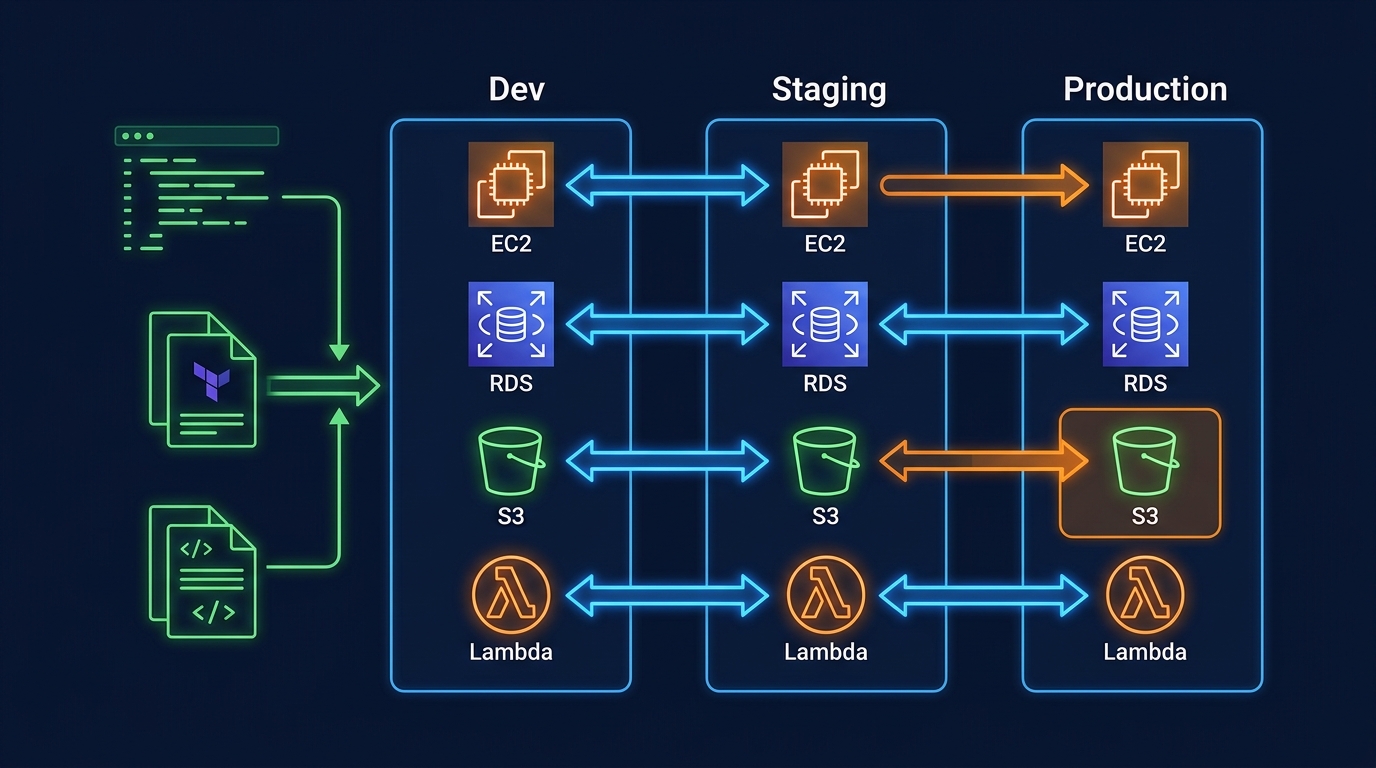
When dev works but production fails, it's almost always an environment parity problem. This guide covers building consistent environments across dev, staging, and prod—and the cost of not doing it.
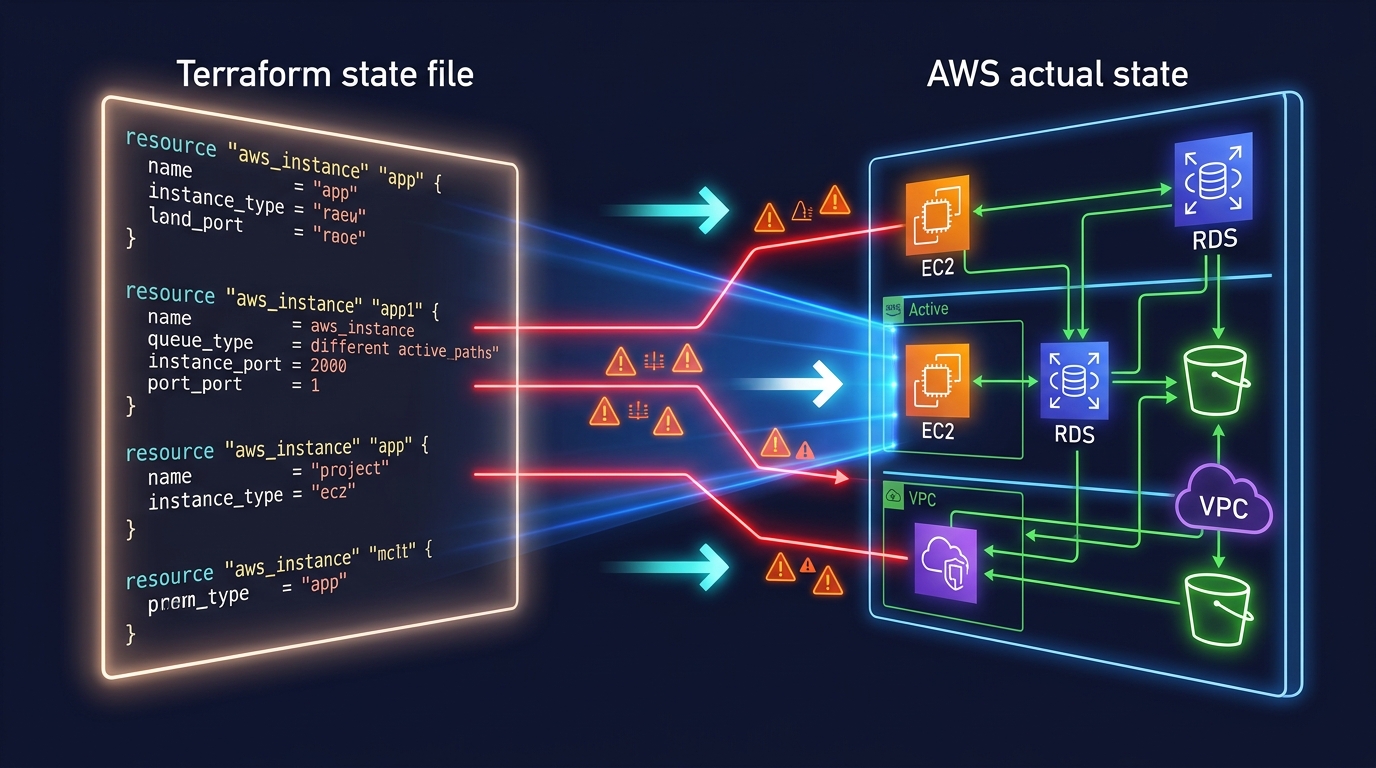
Infrastructure drift—when your actual AWS resources differ from what your IaC declares—causes silent failures and makes disaster recovery impossible. Learn how to detect drift systematically and fix it before it breaks production.
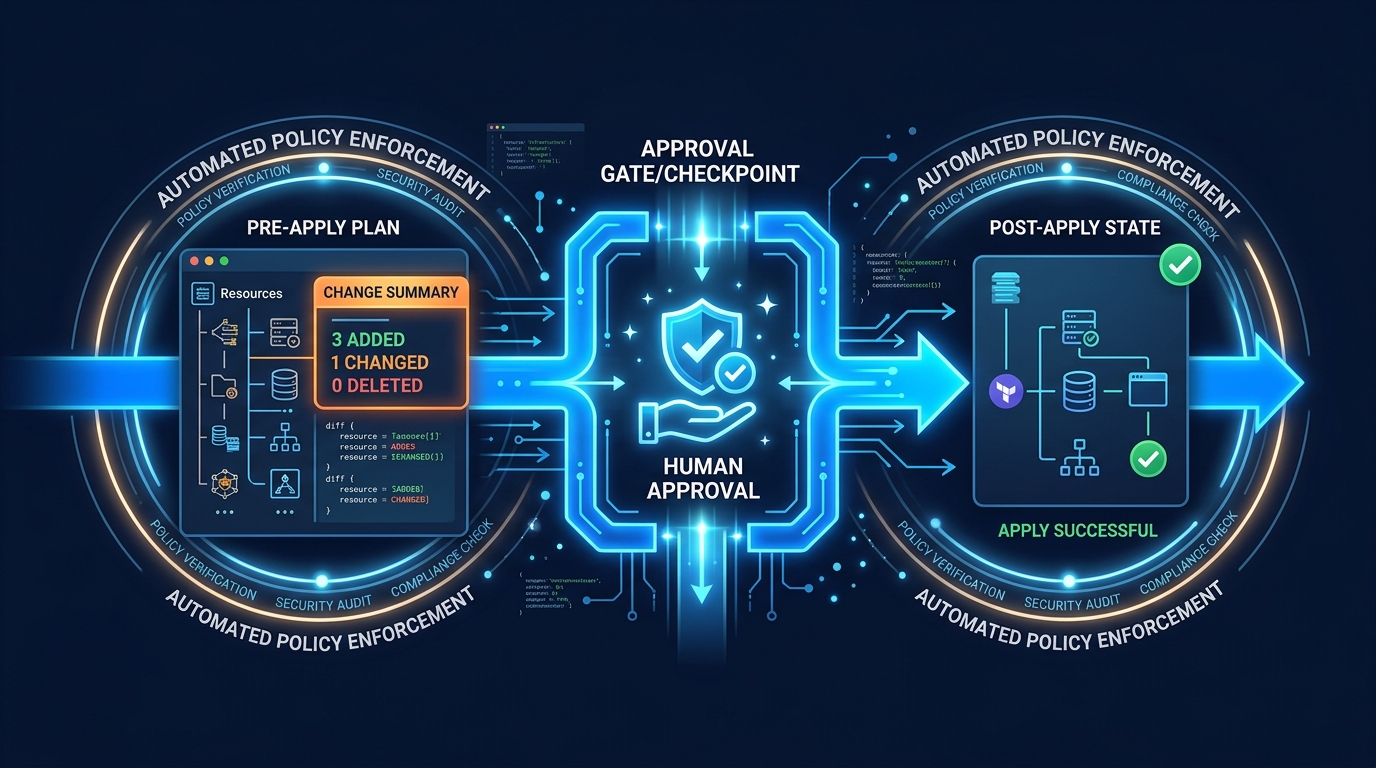
One bad `terraform apply` can delete your database, destroy your application load balancer, or lock your team out of AWS. This guide covers the approval gates, plan review processes, and safety tools that prevent infrastructure disasters.
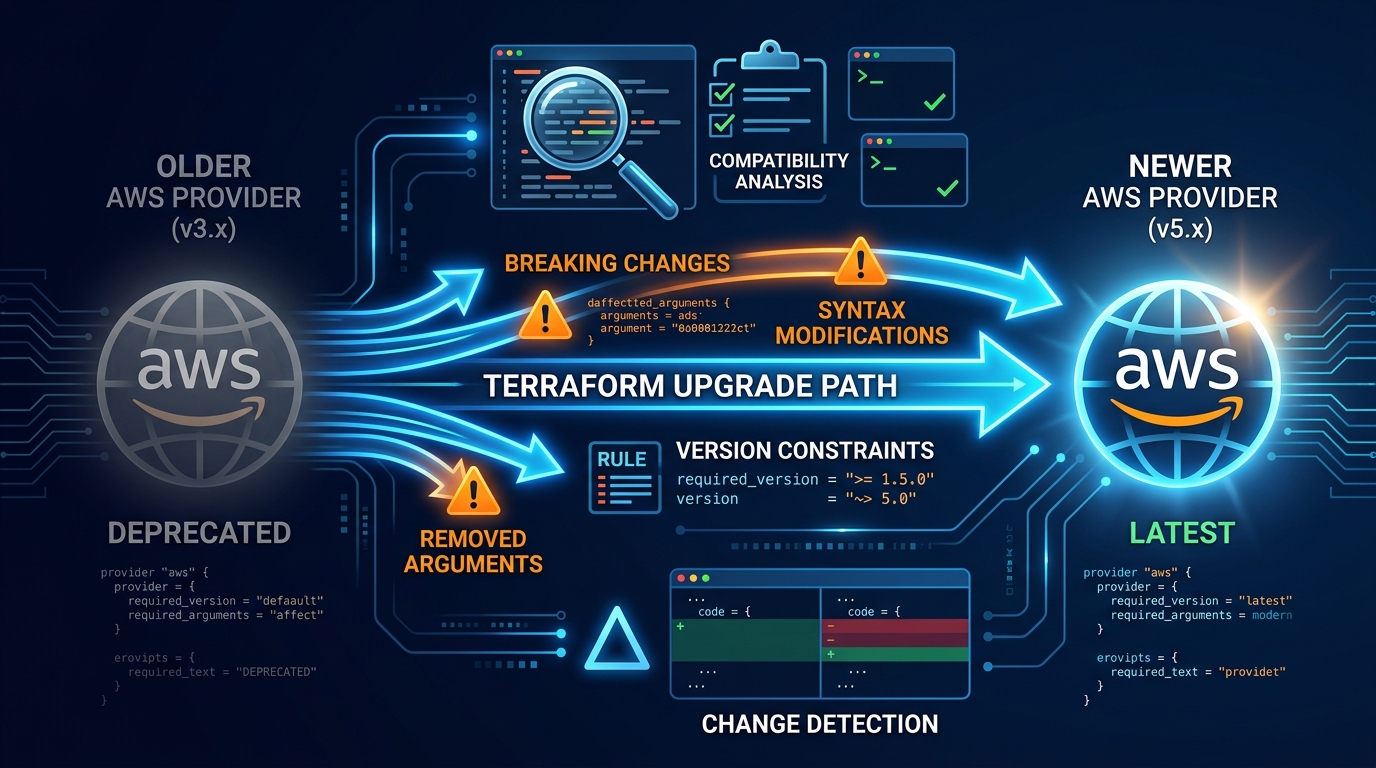
Most teams are 2-3 major AWS provider versions behind. Old providers miss new AWS features, have security risks, and diverge from current best practices. This guide covers how to audit, upgrade, test, and rollback safely.
Terraform state is the source of truth for your infrastructure. When it breaks, your entire IaC strategy breaks with it. This guide covers state imports, moves, emergency repairs, and the backend best practices that prevent state disasters on AWS.
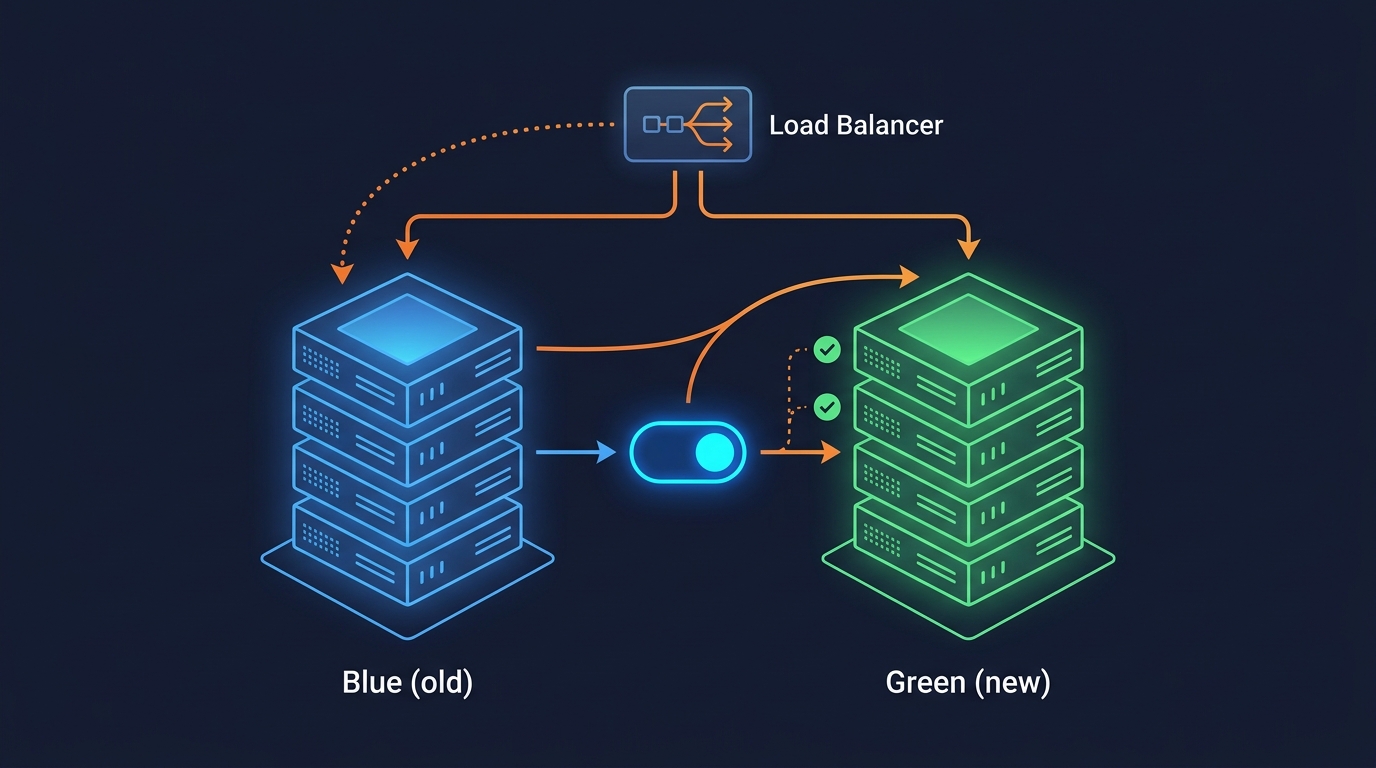
Blue/green deployments eliminate downtime by running two identical production environments. Traffic switches from blue (old) to green (new) instantly. This guide covers CodeDeploy automation, health check validation, and rollback strategies for zero-downtime releases on AWS ECS.

CI/CD infrastructure is invisible until your DevOps bill hits $15,000/month. Build minutes, artifact storage, and ephemeral environments accumulate costs that few teams track. Here is how to measure and control them.
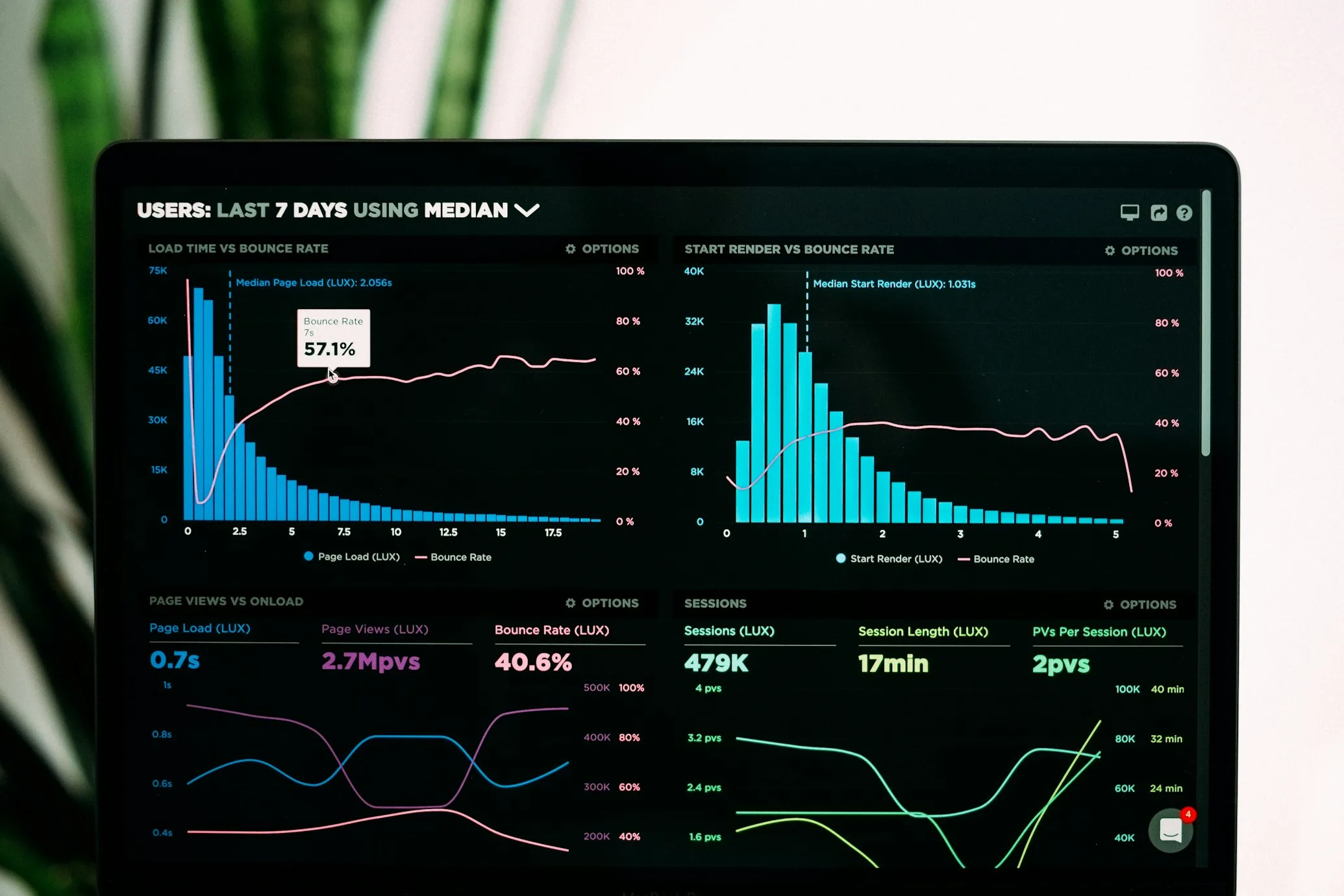
A 500ms latency spike in a distributed system could be a slow RDS query, a Lambda cold start, a downstream API timeout, or a CloudWatch Logs ingestion delay. Finding the cause requires correlated logs, traces, and metrics — not grep.
We use cookies and similar technologies to analyze site traffic, personalize content, and provide social media features. By clicking "Accept," you consent to our use of cookies. You can adjust your preferences at any time.