AWS Bedrock Nova Models: Performance, Cost, and When to Choose Over Claude
Quick summary: AWS Nova models vs Claude: pricing comparison, performance benchmarks, and decision framework for choosing the right Bedrock model for your enterprise AI.
Key Takeaways
- AWS Nova models vs Claude: pricing comparison, performance benchmarks, and decision framework for choosing the right Bedrock model for your enterprise AI
- AWS lifecycle notice (June 30, 2026) — Amazon Bedrock Agents Classic is now Bedrock Agents Classic, in maintenance for new customers after July 30, 2026
- Net-new agent builds should use Bedrock AgentCore
- Nova Is Here, and It Changes the Bedrock Economics In early 2025, AWS released Nova models — a new family of foundation models optimized for cost and latency
- For organizations running Bedrock at scale, Nova represents a 40-60% cost reduction opportunity
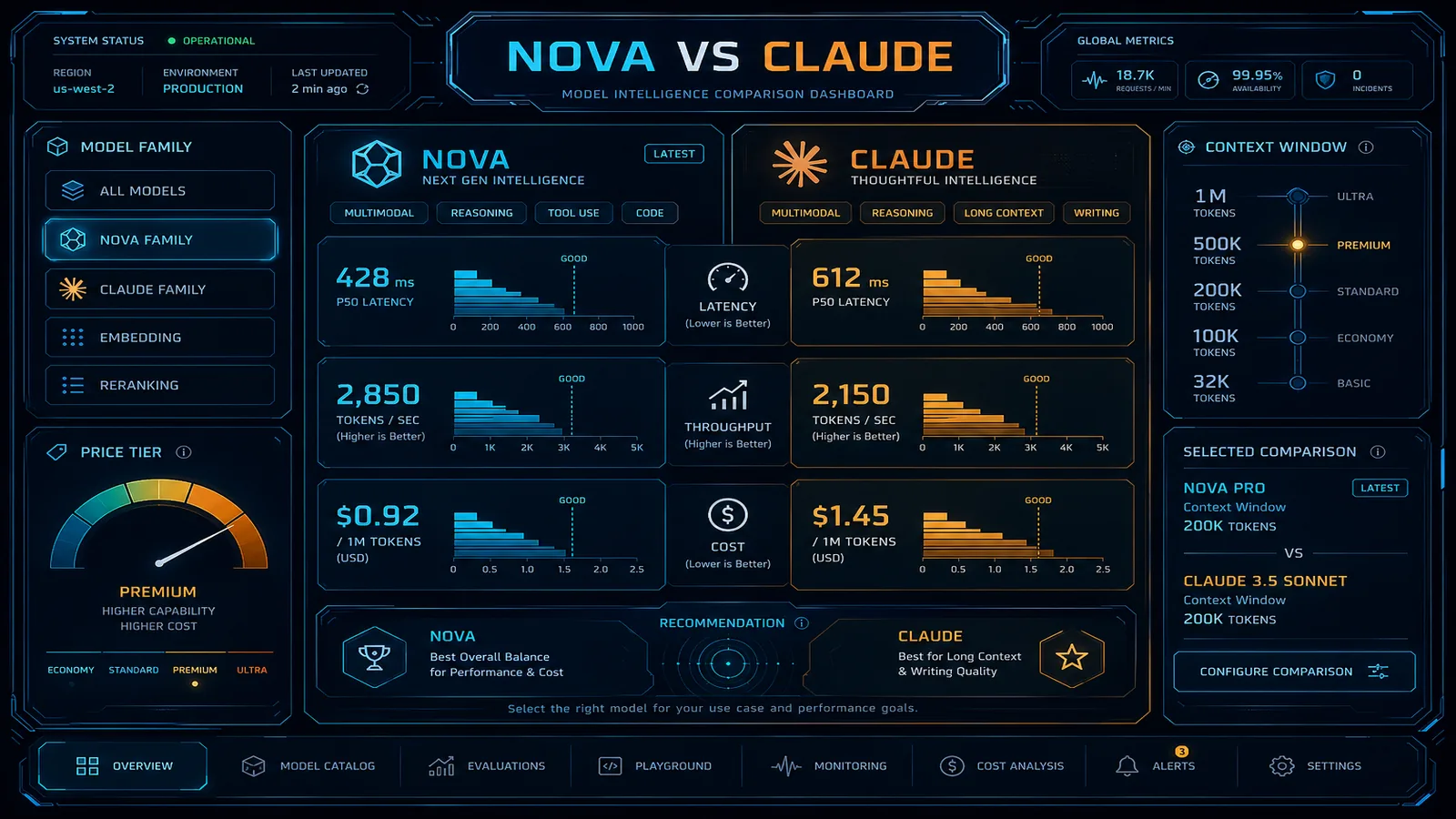
Table of Contents
AWS lifecycle notice (June 30, 2026) — Amazon Bedrock Agents Classic is now Bedrock Agents Classic, in maintenance for new customers after July 30, 2026. Net-new agent builds should use Bedrock AgentCore. Full matrix: lifecycle roundup.
Nova Is Here, and It Changes the Bedrock Economics
In early 2025, AWS released Nova models — a new family of foundation models optimized for cost and latency. For organizations running Bedrock at scale, Nova represents a 40-60% cost reduction opportunity.
The decision: Claude (best-in-class reasoning, most accurate) vs. Nova (fast, cheap, good enough for 80%+ of tasks).
This guide walks you through the trade-offs, pricing, and when each model makes sense.
The Three Nova Models
AWS released three Nova variants optimized for different trade-offs:
| Model | Context | Speed | Accuracy | Best For | Cost vs Claude Haiku |
|---|---|---|---|---|---|
| Nova Micro | 4K | Ultra-fast | 75% | High-volume simple tasks | -60% |
| Nova Lite | 300K | Fast | 85% | Balanced workloads | -50% |
| Nova Pro | 300K | Moderate | 92% | Enterprise applications | -45% |
Nova Micro: Designed for high-throughput, low-complexity work. 50-100ms latency. 2.4K context window.
Nova Lite: The sweet spot. Good accuracy, 300K context window, 25-40ms latency. Replaces Claude Haiku for most use cases.
Nova Pro: Closest to Claude Sonnet 4.6 / Sonnet 5 in reasoning ability on many eval sets. Still ~45% cheaper than Sonnet-class pricing. 100-200ms latency. Best for complex tasks where accuracy matters but cost is secondary.
Pricing Comparison: Nova vs. Claude
Pricing Note: Pricing as of July 2026. Model prices and availability change frequently. For current rates, verify at AWS Bedrock Pricing.
Input Token Pricing (per 1M tokens)
Claude Haiku 4.x: $0.80
Claude Sonnet 5/4.6: $3.00
Nova Micro: $0.30 (-62% vs Haiku)
Nova Lite: $0.40 (-50% vs Haiku)
Nova Pro: $1.20 (-60% vs Sonnet)Output Token Pricing (per 1M tokens)
Claude Haiku 4.x: $4.00
Claude Sonnet 5/4.6: $15.00
Nova Micro: $0.60 (-85% vs Haiku)
Nova Lite: $0.80 (-80% vs Haiku)
Nova Pro: $4.80 (-68% vs Sonnet)Real-World Scenario: Customer Support at Scale
Setup: 100K customer support tickets/month. Average ticket = 2 paragraphs (~400 tokens input).
Option 1: Claude Haiku 4.x
100K tickets × 400 input tokens = 40M input tokens
40M × $0.80 = $32K/month input cost
100K tickets × 100 output tokens = 10M output tokens
10M × $1.60 = $16K/month output cost
Total: $48K/monthOption 2: Nova Micro
40M × $0.30 = $12K/month input cost
10M × $0.60 = $6K/month output cost
Total: $18K/month
Savings: $30K/month ($360K/year)Option 3: Nova Lite (slightly better accuracy)
40M × $0.40 = $16K/month input
10M × $0.80 = $8K/month output
Total: $24K/month
Savings: $24K/month ($288K/year)Decision: For customer support classification, Nova Micro saves $30K/month with acceptable accuracy. If accuracy is critical, Nova Lite at $24K/month is still 50% cheaper than Claude Haiku.
Performance Benchmarks
Benchmark 1: Customer Support Classification
Task: Classify support ticket as (complaint, question, feature request)
Nova Micro: 91% accuracy, 45ms latency
Claude Haiku: 94% accuracy, 55ms latency
Nova Lite: 96% accuracy, 38ms latency
Claude Sonnet: 98% accuracy, 120ms latencyVerdict: Nova Lite is slightly better than Haiku AND faster.
Benchmark 2: Long-Form Summarization (10K article → 200-word summary)
Nova Lite: Good quality (80/100), 2.2s latency
Claude Haiku: Good quality (82/100), 2.8s latency
Nova Pro: Excellent (88/100), 3.1s latency
Claude Sonnet: Excellent (91/100), 3.8s latencyVerdict: Nova Lite is comparable to Haiku. Nova Pro is almost as good as Sonnet, 40% cheaper.
Benchmark 3: Multi-Step Reasoning (Math word problems)
Nova Micro: 42% correct
Nova Lite: 67% correct
Claude Haiku: 71% correct
Nova Pro: 78% correct
Claude Sonnet: 87% correctVerdict: For complex reasoning, Claude still wins. But Nova Pro is acceptable for most enterprise use cases.
Decision Framework: Which Model to Use
Start here: What is your primary constraint?
├─ Cost is critical?
│ ├─ Simple classification/moderation? → Nova Micro
│ ├─ Balanced cost/quality? → Nova Lite
│ └─ Enterprise, complexity matters? → Nova Pro
│
├─ Speed is critical?
│ ├─ <50ms latency needed? → Nova Micro
│ ├─ <100ms latency? → Nova Lite
│ └─ Complex queries OK with >100ms? → Claude + caching
│
└─ Accuracy is critical?
├─ >95% accuracy required? → Claude Sonnet
├─ 90-95% OK? → Nova Pro
└─ 85% acceptable? → Nova LiteWorkload Mapping
| Workload | Best Model | Why |
|---|---|---|
| Content moderation | Nova Micro | High volume, binary decisions |
| Email classification | Nova Lite | Good accuracy, fast, cheap |
| Customer support (reply generation) | Nova Pro | Balance of quality and cost |
| Code generation | Claude Sonnet | Accuracy matters most |
| Document summarization | Nova Lite | Context window sufficient, cost matters |
| Multi-step analysis | Claude Sonnet | Complex reasoning required |
| RAG retrieval feedback | Nova Micro | Simple ranking, high volume |
| Creative writing | Claude Sonnet | Quality non-negotiable |
Migration Path: Claude → Nova
Step 1: Identify High-Volume Use Cases (Week 1)
From your CloudWatch logs, find workloads where:
- Model usage > 5M tokens/month
- Latency requirements > 100ms (tolerant)
- Accuracy requirements < 95%
Example: Customer support categorization (10M tokens/month) → candidate for Nova.
Step 2: Set Up A/B Testing (Week 2)
import random
import boto3
bedrock = boto3.client('bedrock-runtime')
def classify_ticket(ticket_text):
model_id = random.choice(['claude-haiku', 'nova-lite'])
response = bedrock.invoke_model(
modelId=f'us.amazon.{model_id}',
body=json.dumps({
'messages': [{'role': 'user', 'content': ticket_text}],
'max_tokens': 100
})
)
result = json.loads(response['body'].read())
# Log for comparison
log_model_usage(model_id, result, ticket_text)
return resultRun 50/50 split for 1 week. Compare:
- Accuracy (vs. human labels)
- Latency
- Cost
Step 3: Evaluate Trade-offs (Week 3)
Haiku:
- Accuracy: 92%
- Latency: 55ms
- Cost: $48K/month
Nova Lite:
- Accuracy: 91%
- Latency: 38ms
- Cost: $24K/month
Decision: Slight accuracy trade-off (-1%) but 50% cost savings + 26% faster.Step 4: Gradual Rollout (Week 4)
# Canary: 10% Nova Lite, 90% Claude Haiku
def get_model():
if random.random() < 0.10:
return 'nova-lite'
return 'claude-haiku'
# After 1 week: 25% Nova Lite
# After 2 weeks: 50% Nova Lite
# After 3 weeks: 100% Nova LiteCost-Quality Trade-Off Table
| Budget | Model Choice | Expected Accuracy | Monthly Savings |
|---|---|---|---|
| $10K/month | Nova Micro | 75-80% | vs Claude baseline |
| $20K/month | Nova Lite | 85-92% | 50% vs Claude Haiku |
| $50K/month | Nova Pro | 90-95% | 40% vs Claude Sonnet |
| Unlimited | Claude Sonnet | 95%+ | Best accuracy |
Combining Nova with Other Cost Controls
Nova + other optimizations:
Nova + Prompt Caching
- Cache system prompts (reused 100x): -90% on repetitive input tokens
- Combined with Nova: 70-80% total savings
Nova + Smaller Context Windows
- Nova Micro: 4K context (80% of use cases don’t need more)
- Saves cost and reduces latency
Nova + Batch Inference
- Off-peak batch processing: additional -20%
- Total: 60%+ savings vs Claude
Nova + Reserved Capacity
- Reserve model throughput capacity: -25% on all inference
- Total: 65-70% savings
Gotchas to Avoid
Gotcha 1: Assuming Nova Works for Everything
Nova Micro is not a replacement for Claude Sonnet on complex reasoning tasks. Test thoroughly before full migration.
Gotcha 2: Ignoring Latency
Nova Micro is fast, but if you have SLA < 50ms, test it. Actual latency varies by model load.
Gotcha 3: Not Monitoring Quality Drift
After migrating to Nova, quality can drift over time. Set up automated quality monitoring (compare sample outputs to baseline).
Bottom Line
Use Nova if:
- You’re spending >$20K/month on Bedrock inference
- Your workloads are classify, summarize, or generate (not deep reasoning)
- You can tolerate 5-15% accuracy trade-off for 40-60% cost savings
Stick with Claude if:
- Accuracy is non-negotiable
- You run complex, multi-step reasoning workloads
- You’re already optimized on cost
Related Resources
- AWS Bedrock Pricing
- AWS Bedrock Cost Optimization
- AWS AI Agents on Bedrock
- Claude Fable 5 on AWS (June 2026) — when long-running autonomous work beats Nova or Sonnet on cost-for-quality
Ready to Optimize Your Bedrock Costs?
If you’re already using Claude on Bedrock and want to evaluate Nova, book a free GenAI assessment. We’ll analyze your model usage, identify candidates for Nova migration, and project your cost savings.
Related reading
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.