Microservices vs Monolith on AWS: Architecture Decision Guide
Quick summary: A practical guide to choosing between monolithic and microservices architectures on AWS — team size, deployment complexity, operational cost, and the patterns that help you choose the right approach for your stage.

Table of Contents
The microservices vs monolith debate is one of the most consequential architecture decisions a team makes — and one of the most frequently made for the wrong reasons. Teams adopt microservices because it is what large companies do, not because their application or organization needs it. The result: distributed system complexity imposed on a five-person team that would ship faster with a well-structured monolith. For organizations moving from legacy systems to cloud-native, this decision sits at the heart of any AWS application modernization effort.
This guide provides a practical decision framework based on team size, application complexity, and operational maturity — not on industry hype.
Defining the Options
Monolith
A single deployable unit containing all application functionality:
Single Application
├── User Management
├── Order Processing
├── Payment Handling
├── Notification Service
├── Reporting
└── Single DatabaseDeployment: One build, one deploy, one process.
On AWS: ECS/Fargate running a single container, or EC2 running a single application process. One RDS database.
Modular Monolith
A monolith with well-defined internal module boundaries:
Single Application
├── modules/
│ ├── users/ (controllers, services, models)
│ ├── orders/ (controllers, services, models)
│ ├── payments/ (controllers, services, models)
│ └── notifications/ (controllers, services, models)
└── Single Database (with schema-per-module)Deployment: Still one deployable unit, but internally organized for potential future decomposition.
On AWS: Same as monolith, but internal code structure enables extracting modules into services later.
Microservices
Multiple independently deployable services, each with its own data store:
User Service → Users Database
Order Service → Orders Database
Payment Service → Payments Database
Notification Service → Notification Queue
↕ (API calls, events, messages)Deployment: Each service has its own build, deploy, and scaling pipeline.
On AWS: Multiple ECS services or Lambda functions, each with its own data store (DynamoDB, RDS, or S3), communicating via API calls, EventBridge, SQS, or SNS.
The Decision Framework
Team Size Is the Primary Factor
| Team Size | Recommended Architecture | Rationale |
|---|---|---|
| 1-5 engineers | Monolith or modular monolith | Microservices overhead exceeds any benefit |
| 5-15 engineers | Modular monolith or selective microservices | Extract high-value services only |
| 15-50 engineers | Microservices for independent team domains | Conway’s Law — architecture should match team structure |
| 50+ engineers | Microservices with platform team | Dedicated infrastructure team to manage complexity |
Why team size matters: Microservices do not reduce complexity — they redistribute it from the codebase to the infrastructure. Debugging a bug across 15 services with distributed tracing is harder than debugging a monolith with a stack trace. The benefit of microservices is organizational: independent teams can deploy independently. If you do not have independent teams, you do not need independent services.
When to Stay Monolithic
- Early-stage product — You are iterating on product-market fit. Refactoring across service boundaries is 10x harder than refactoring within a monolith.
- Small team — Under 5 engineers, the operational overhead of multiple services, databases, and CI/CD pipelines slows you down.
- Uncertain domain boundaries — If you do not know where the natural service boundaries are, do not guess. Build a monolith, observe the usage patterns, and decompose when boundaries become clear.
- Simple domain — CRUD applications with straightforward data models do not benefit from service decomposition.
When to Adopt Microservices
- Independent scaling requirements — One component needs 100x the compute of another (e.g., video transcoding vs user authentication).
- Independent deployment velocity — Teams need to deploy their components without coordinating with other teams.
- Technology diversity — Different components benefit from different languages, frameworks, or data stores (ML in Python, API in Node.js, batch processing in Java).
- Fault isolation — A failure in one component must not cascade to others (payment processing must not be affected by a reporting bug).
- Organizational structure — Multiple teams own different business domains and need autonomous delivery.
Architecture Comparison on AWS
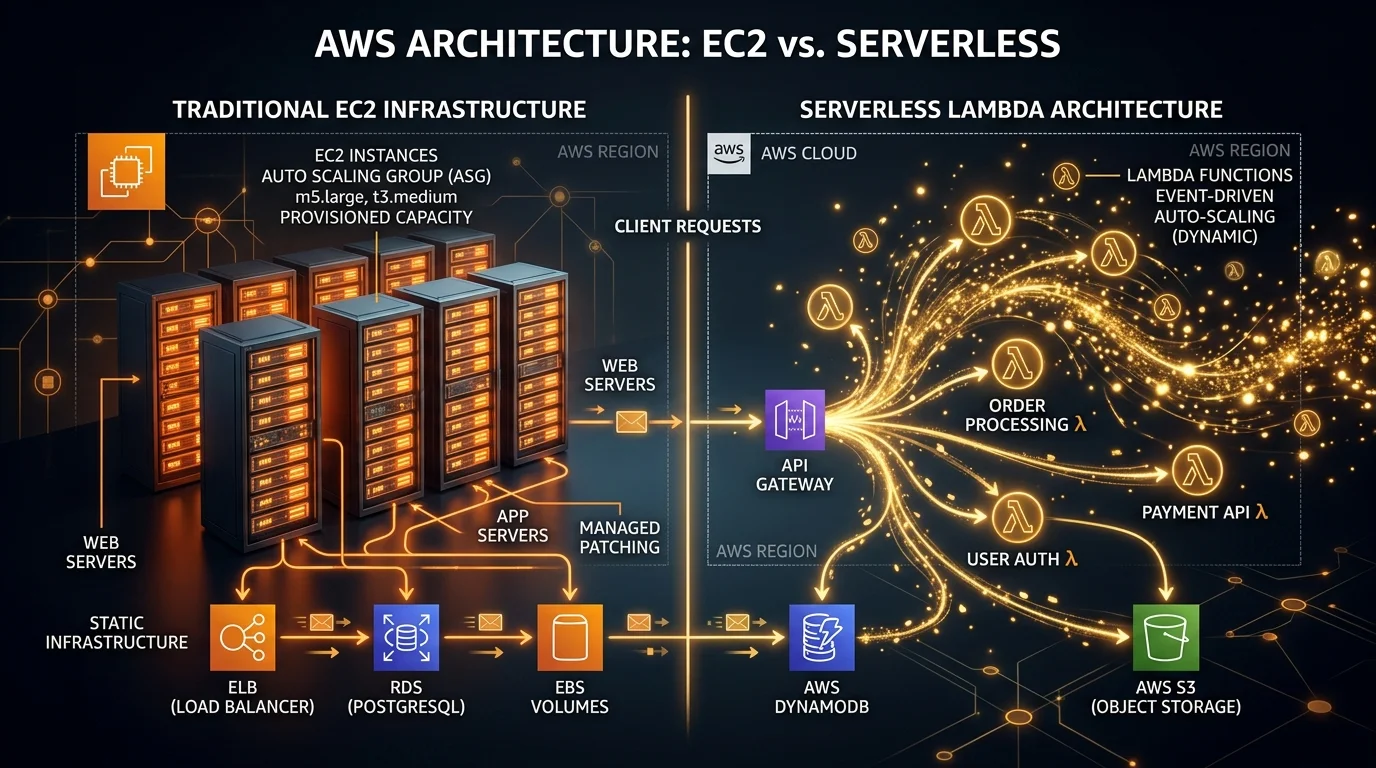
Monolith on AWS
CloudFront → ALB → ECS/Fargate (single service) → RDS (single database)Infrastructure:
- 1 ECS service with auto-scaling
- 1 RDS instance (Multi-AZ for production)
- 1 ALB
- 1 CI/CD pipeline
Cost (typical startup): $300-$800/month
- ECS/Fargate: $150-$400
- RDS: $100-$300
- ALB: $20-$50
- Other: $30-$50
Operational complexity: Low. One service to monitor, one database to back up, one pipeline to maintain.
Microservices on AWS
CloudFront → ALB → ECS Service A → DynamoDB
→ ECS Service B → RDS
→ ECS Service C → DynamoDB
API Gateway → Lambda Service D → DynamoDB
EventBridge → Lambda Service E → SQS → Lambda Service F → S3Infrastructure:
- 5+ ECS services or Lambda functions, each with auto-scaling
- 3+ databases (DynamoDB tables, RDS instances)
- 1-2 ALBs + API Gateway
- EventBridge, SQS, SNS for inter-service communication
- 5+ CI/CD pipelines
- Distributed tracing (X-Ray)
- Service mesh or API gateway for service-to-service communication
Cost (same application as microservices): $800-$3,000/month
- Multiple ECS services: $400-$1,500
- Multiple databases: $200-$800
- Messaging (EventBridge, SQS): $50-$200
- ALB + API Gateway: $50-$150
- Monitoring (X-Ray, CloudWatch): $50-$150
- Other: $50-$200
Operational complexity: High. Multiple services to monitor, multiple databases to back up, multiple pipelines to maintain, distributed debugging, inter-service communication failures.
Serverless Microservices on AWS
API Gateway → Lambda A → DynamoDB
→ Lambda B → DynamoDB
→ Lambda C → DynamoDB
EventBridge → Lambda D → SQS → Lambda E → S3
Step Functions → Lambda F → Lambda G → SNSAdvantages over container-based microservices:
- No ECS cluster management
- Per-request pricing (cost scales linearly with usage)
- Automatic scaling (no capacity planning)
- Simpler CI/CD (deploy individual functions)
Disadvantages:
- Cold starts affect latency
- 15-minute execution limit
- Debugging distributed Lambda functions is harder than debugging containers
- Vendor lock-in deeper than containers
Cost (same application, serverless): $50-$500/month at moderate traffic
- Lambda: $20-$200 (pay-per-request)
- DynamoDB: $20-$200 (on-demand)
- API Gateway: $10-$50
- EventBridge, SQS: $5-$30
- Other: $5-$20
Serverless microservices are significantly cheaper at low-to-moderate traffic because you pay nothing when idle. At very high traffic (millions of requests per hour), container-based microservices may be cheaper due to more efficient compute pricing.
The Modular Monolith: The Best of Both
The modular monolith is the most underrated architecture pattern. It gives you monolith simplicity now with a clear path to microservices later:
Implementation:
- Module boundaries — Organize code into modules by business domain (users, orders, payments)
- Module interfaces — Modules communicate through defined interfaces, not by reaching into each other’s code
- Module databases — Each module owns its database schema (separate schemas within the same RDS instance)
- No circular dependencies — Module A can call Module B, but Module B cannot call Module A without going through an event
Extraction path: When a module needs to become a service (independent scaling, different deployment cadence), extract it:
Before: Monolith → [Users module, Orders module, Payments module] → Single DB
After: Monolith → [Users module, Orders module] → DB Schema A
Payment Service (extracted) → DB Schema B
EventBridge connecting themThe key insight: It is much easier to extract a well-defined module from a monolith into a service than to merge poorly separated microservices back into a coherent system. Start modular, decompose selectively.
Selective Decomposition
Instead of migrating entirely to microservices, extract only the components that benefit from independence:
Good Extraction Candidates
- Compute-intensive tasks — Image processing, video transcoding, ML inference → Extract to Lambda or Fargate with independent scaling
- Third-party integrations — Payment gateways, email providers, SMS → Extract to isolate failure and rate limits
- Event consumers — Analytics, notifications, audit logging → Extract as EventBridge consumers that process events asynchronously
- Batch processing — Report generation, data exports, ETL → Extract to Step Functions workflows
Poor Extraction Candidates
- Tightly coupled CRUD — If two modules share the same database tables and queries join across them, extracting one creates a distributed join problem
- Synchronous chains — If Service A always calls Service B, which always calls Service C, you have a distributed monolith with extra latency
- Low-traffic modules — Modules that handle 10 requests per day do not benefit from independent scaling
Operational Requirements by Architecture
| Capability | Monolith | Modular Monolith | Microservices |
|---|---|---|---|
| CI/CD pipelines | 1 | 1 | 5-20+ |
| Database management | 1 database | 1 database (multiple schemas) | 5-20+ data stores |
| Monitoring | Single APM setup | Single APM setup | Distributed tracing required |
| Debugging | Stack traces | Stack traces | Correlation IDs across services |
| Disaster recovery | One recovery plan | One recovery plan | Per-service recovery plans |
| Team coordination | High (shared codebase) | Moderate (module interfaces) | Low (API contracts) |
| Deployment risk | All-or-nothing | All-or-nothing | Per-service (lower blast radius) |
| DevOps maturity needed | Basic | Basic | Advanced |
Common Mistakes
Mistake 1: Premature Microservices
The most common mistake — decomposing into microservices before understanding the domain. The result is services with the wrong boundaries, excessive inter-service communication, and distributed data consistency problems that would not exist in a monolith.
Rule of thumb: If you have not built the monolith first, you do not know where the service boundaries should be.
Mistake 2: Distributed Monolith
Microservices that must be deployed together, share a database, or fail together are a distributed monolith — the worst of both worlds. You get microservices complexity without microservices benefits.
Test: Can each service be deployed independently without coordinating with other services? If not, you have a distributed monolith.
Mistake 3: Ignoring Data Ownership
The hardest part of microservices is data decomposition. If two services share a database, changes to one service’s schema can break the other. Each service must own its data exclusively, communicating through APIs or events — never through shared database access.
Mistake 4: Over-Engineering Communication
Simple HTTP/REST calls between services are fine for synchronous request-response patterns. You do not need Kafka, gRPC, or service mesh on day one. Start with HTTP calls and SQS/EventBridge for async, and add complexity only when you hit specific performance or reliability problems.
Getting Started
Start with a monolith. Make it modular. Extract services when — and only when — a specific module needs independent scaling, deployment, or technology. This approach delivers the simplest possible architecture at every stage of your growth.
For organizations looking to modernize legacy applications into cloud-native architectures, see our AWS Application Modernization services. For architecture design, including the monolith-to-microservices transition, see our AWS Architecture Review. For serverless microservices implementation, see our AWS Serverless Architecture Services.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.