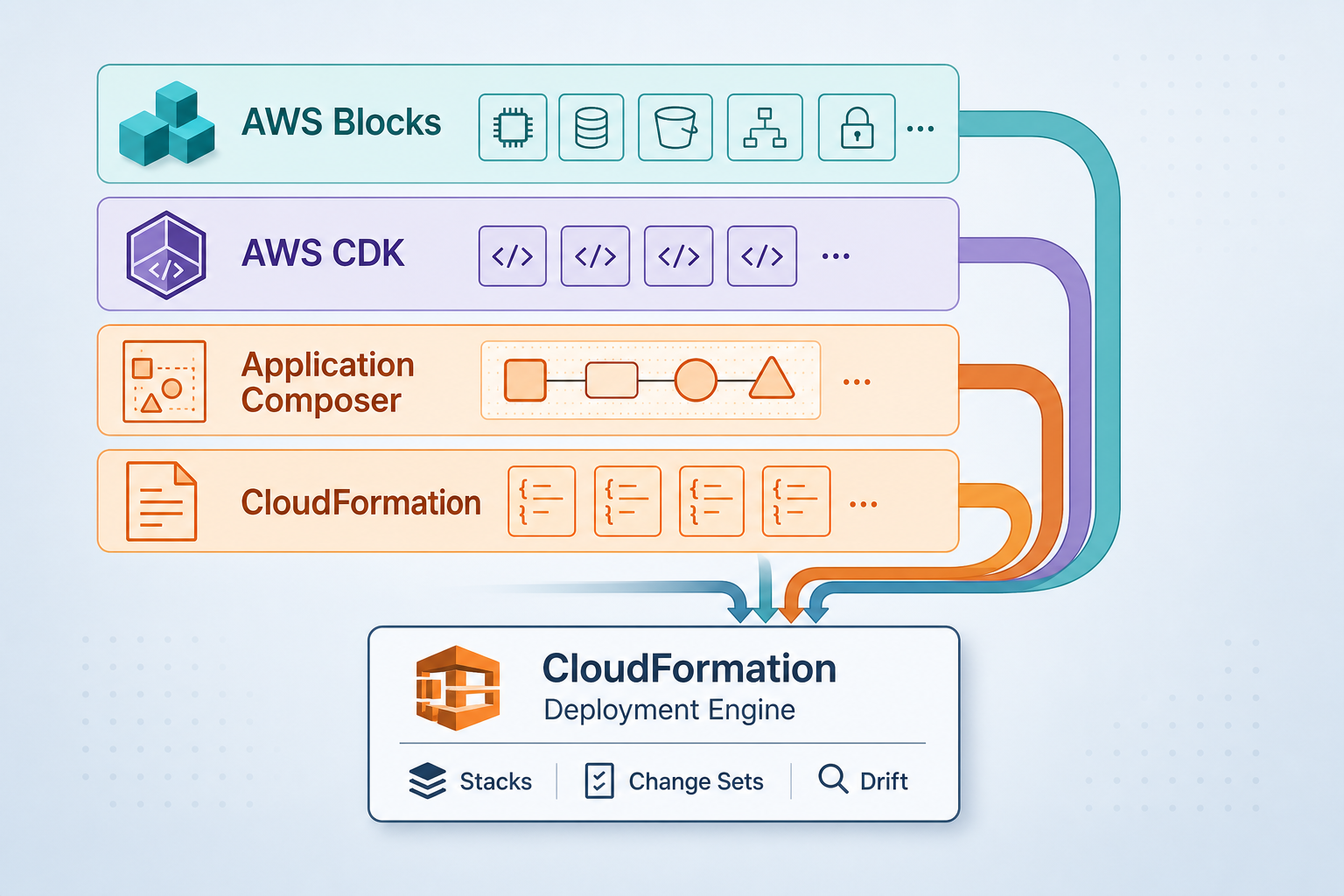
Prometheus Cardinality Explosion on AWS: AMP, EMF, and Cost-Aware Metrics
Quick summary: That `user_id` label on every HTTP metric turns Amazon Managed Prometheus into a five-figure line item. This guide explains cardinality mechanics, EMF vs remote write, and Application Signals defaults worth disabling.
Key Takeaways
- That `user_id` label on every HTTP metric turns Amazon Managed Prometheus into a five-figure line item
- Amazon Managed Prometheus (AMP) pricing (June 2026) scales with metrics ingested and stored—cardinality is dollars
- Benchmark pattern — OTel demo workload on EKS: enabling with raw URL paths pushed active series from 12k → 890k in 6 h; AMP estimate +$2,400/mo
- Relabel to template routes ( ) restored 14k series
- See observability beyond CloudWatch for stack wiring

Table of Contents
Amazon Managed Prometheus (AMP) pricing (June 2026) scales with metrics ingested and stored—cardinality is dollars. A single histogram with path label including UUIDs can create millions of active series within hours.
Benchmark pattern — OTel demo workload on EKS: enabling
http.routewith raw URL paths pushed active series from 12k → 890k in 6 h; AMP estimate +$2,400/mo. Relabel to template routes (/users/{id}) restored 14k series. See observability beyond CloudWatch for stack wiring.
Symptom → mechanism → AWS control
| Production symptom | Mechanism | AWS control |
|---|---|---|
| Observability bill exceeds compute | High-cardinality labels (user_id, pod) | AMP relabel_configs drop, aggregate recording rules |
| CloudWatch PutMetricData throttled | Custom metric cardinality limits | EMF embedded metrics with bounded dimensions |
| Dashboard slow to load | Million-series PromQL scan | AMP query logging, cardinality governance policy |
Opinionated take: Treat metric labels like database indexes—approve new high-cardinality labels in review, and drop pod-name from application metrics at scrape time.
Mechanism
Prometheus identifies a time series by metric name + label set. Each unique combination is billed storage and query cost. High-cardinality labels (IDs) multiply series combinatorially with other labels (status, method, pod).
AWS controls
| Approach | Service | Use when |
|---|---|---|
| Managed backend | AMP + AMG | EKS/ECS metrics at scale |
| Embedded metrics | CloudWatch EMF | Lambda/custom apps without scrape |
| SLO-native | Application Signals | Service golden signals—watch auto-discovered ops |
| Cost guard | Metric filters + alarms on IncomingLogEvents / AMP workspace limits | FinOps gate |
Opinionated take: Relabel at the collector (ADOT) before remote_write—do not fix cardinality in Grafana dashboards.
AWS services map
| Need | Service | Skip when |
|---|---|---|
| Cardinality control | AMP + relabel/aggregate rules | CloudWatch only with <10 custom metrics |
| Cost attribution | Cost and Usage Report + AMP usage metrics | Single-service app with default metrics |
| FinOps guardrails | CloudWatch anomaly detection on AMP spend | Pre-production with negligible ingest |
When this advice breaks
- Short-lived batch jobs — High churn series may be acceptable if retention is 24h and jobs are few.
- Debugging incidents — Temporary high-cardinality scrape OK with documented TTL and owner.
What to do this week
- Export top 20 labels by series count from AMP or Prometheus
label_valuessampling. - Add
drop/labelmapprocessors in ADOT config for forbidden labels (user_id,trace_id). - Set CloudWatch alarm on AMP
DiscardedSamplesor workspace ingestion rate spike. - Pair with log sampling guide (part 3 of this track).
More in This Track
Part of the Engineering Guides library (June 2026).
- Previous: Part 1
- Next: Part 3
- Browse tracks: Engineering Guides hub
What this guide doesn’t cover
Distributed tracing propagation—see part 1 OTel guide in this track.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.