Data Center Exit on AWS (2026): Wave Design, the 22-Month Program, and Why Big-Bang Cutovers Fail on People Before Tech
Quick summary: A composite mid-market manufacturer exited a colo of 150 workloads and ~400 TB in 21 months across 8 waves, with 47 minutes of unplanned cutover downtime (industry median per Gartner: ~4 hours per major cutover). The single-wave alternative bid came in at ~$4.8M; the wave-based program ran ~$2.1M. Here is how the wave plan, dependency cutoff, and rollback layer fit together against a hard landlord deadline.
Key Takeaways
- The single-wave alternative bid came in at ~$4
- 8M; the wave-based program ran ~$2
- 1M
- AWS lifecycle notice (June 30, 2026) — AWS Directory Service Simple AD is in maintenance for new customers after July 30, 2026
- We are mid-cycle on a wave of large data centre exits — programs that look nothing like the 2018 "5-year lift-and-shift" projects and everything like wave-based, deadline-driven programs of work
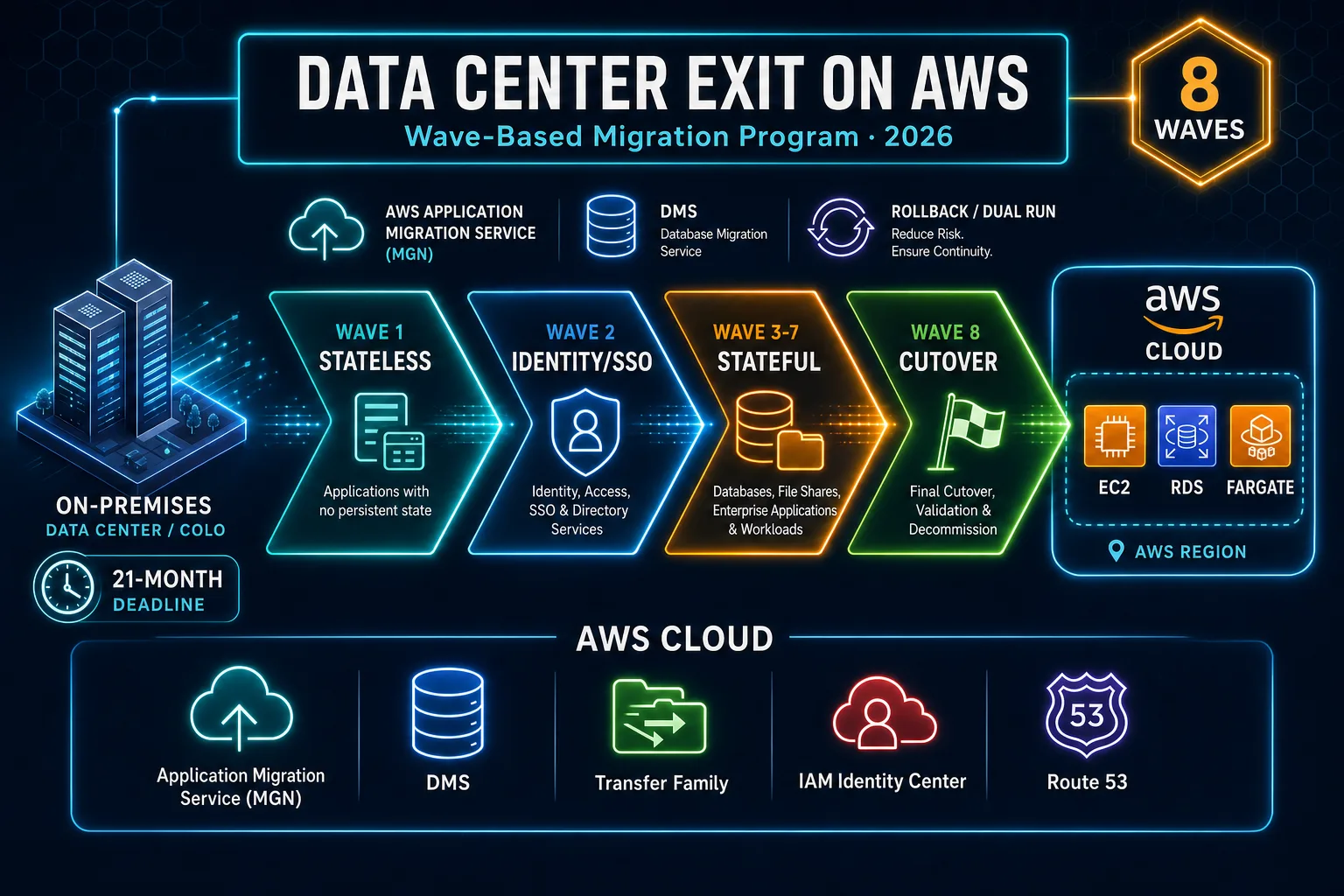
Table of Contents
AWS lifecycle notice (June 30, 2026) — AWS Directory Service Simple AD is in maintenance for new customers after July 30, 2026. Net-new directory workloads should use Managed Microsoft AD or AD Connector. Full matrix: lifecycle roundup.
By June 2026, AWS has shipped the second-generation Application Migration Service (MGN) console refresh and tightened MAP funding gates, and meanwhile lease and colo contracts signed in the 2021–2023 wave are now expiring. We are mid-cycle on a wave of large data centre exits — programs that look nothing like the 2018 “5-year lift-and-shift” projects and everything like wave-based, deadline-driven programs of work. This is for CIO offices, program directors, and platform leads running one of those exits — not a migration strategy explainer, and not the cloud-exit reversibility post (which is the opposite problem: making AWS workloads portable). This is the program-management view of moving 100+ workloads off on-prem onto AWS before the landlord clock runs out.
Benchmark pattern (not a cited client) — A composite mid-market manufacturer: 150 workloads (mix of ERP application + database tier, MES, SCADA gateways, file shares, BI, source control), ~400 TB of stateful data, primary DC + 2 regional DR sites, 24-month colo contract exit deadline. Program completed in 21 months across 8 waves. Unplanned cutover downtime across the entire programme: ~47 minutes (Gartner’s median per major cutover is ~4 hours, so ~32 hours expected across 8 waves). Total program cost: ~$2.1M (labour + AWS + tooling) vs a prior bid of ~$4.8M from a tier-1 SI that proposed a single-wave plan. Numbers come from the wave plan template; plug in your own estate to size the budget envelope.
The DC-exit clock is the only deadline that matters — design backwards from it
A data centre exit programme has exactly one hard constraint: the landlord’s notice-period clock. Everything else — cloud architecture preferences, vendor timelines, internal politics — bends to that date. Design the programme by working backwards:
- Notice + decommission window at the end. 30–90 days for physical decommission, certified destruction, and lease-exit paperwork. Read the lease — many require months of written notice before the end date.
- Steady-state proving window before that. 30 days of all workloads green on AWS, no source-side running, before you trigger decom.
- 8–10 waves before that, sized 8–15 workloads each, with 2–4 weeks between waves for retrospective + next-wave readiness.
- Pre-Wave 1 foundation phase before that: landing zone, network baseline, identity, observability, FinOps tagging, runbook templates, and the risk register.
If the math doesn’t fit, the programme is either over-scoped or under-resourced. Wave-based exits typically run 18–30 months; below 12 months you are not running a programme, you are running an incident response, and the playbook is different.
Wave design: 8–15 workloads, one dependency cutoff, one rollback layer
Every wave answers three questions: what moves, how it moves, how it un-moves. The wave plan template captures these as columns; the structure that matters:
| Wave design constraint | What to set | Why |
|---|---|---|
| Size | 8–15 workloads | Below 8, programme overhead dominates; above 15, dependency analysis becomes intractable and on-call burns out |
| Theme | One narrative (“low-risk lift-and-shift”, “file share + identity prep”, “stateful core”) | Reduces context-switching for the cutover team; lets you reuse the runbook template across waves |
| Dependency cutoff | No wave depends on un-migrated work outside its scope | If Wave 3 needs Wave 5’s SSO, Wave 3 either waits or owns a minimal SSO of its own |
| Rollback layer | One named per wave (DNS swap, blue/green ALB, on-prem standby, CDC replication) | Rollback is not a single button; it’s a documented layer with a trigger condition |
| Decom date | 30/60/90/120 days after cutover by criticality | Critical waves keep source warm for 90+ days; lift-and-shift can decom at T+30 |
The opinionated take: size waves to similar criticality. Mixing a low-risk wiki cutover with a high-stakes ERP cutover in the same wave produces a runbook that either over-protects the wiki or under-protects the ERP. Keep them in separate waves with separate runbooks. The wave template above shows this — Waves 1, 6, and 8 are low-risk; Waves 4, 5, and 7 are high-stakes.
The four windows you must define before Wave 1
Programme planning fails most often at window definition. The four windows below are not the same thing, and conflating them produces miscommunication with stakeholders. Define each one explicitly in the master timeline.
- Discovery window — the time between identifying a workload as in scope and starting its wave preparation. Typically 6–12 weeks per workload. The bottleneck is rarely tooling; it is the workload owner’s availability for design conversations.
- Dual-run window — the period during which the workload is operational on both source (on-prem) and target (AWS). Sized by replication tooling capacity and the lag SLA: typically 2–6 weeks for replatform waves, longer for stateful databases. This is also when most of your data-egress cost lands — budget for it.
- Cutover window — the actual maintenance window during which writes are paused on source, replication catches up, and traffic redirects to target. 2–8 hours for most waves; up to a long weekend for stateful cores like ERP databases.
- Decommission window — the time between successful cutover and physical decom of source. This is your rollback runway. Setting it too short (e.g. < 30 days for a critical workload) trades cost for risk in the wrong direction.
The mistake we have seen: programmes that conflate “cutover window” with “go-live decision” and decommission the source the day after the cutover. The first incident in the post-cutover steady-state then has no rollback, and the programme has to invent one in real time.
What the data tells you to move first — and what to move last
A wave ordering exists in every programme that is empirically defensible, not just opinion. The data points come from the migration-readiness assessment (readiness checklist), the dependency-flow analysis, and the team’s first-hand experience of which workloads have the fewest unknowns.
Move first:
- Workloads with low criticality and few dependencies — Wave 1 is the cutover muscle, not the value delivery wave.
- Identity and SSO — Wave 2 typically. Every customer-facing wave from Wave 3 onwards depends on it.
- Internal-only tools with no customer impact — they prove the network and observability stack without putting customer trust at stake.
Move in the middle:
- Customer-facing web tier — proves the cutover model to customers and unlocks revenue-tier confidence.
- Reporting and analytics — relatively isolated, but stateful, so they exercise the data-migration pattern before the core stateful waves.
- Integration / API tier — depends on web and identity; needs careful trading-partner comms.
Move last:
- Stateful core — ERP, primary database, MES — these have the longest dual-run, the most complex rollback, and the highest stakes.
- Decommission + monitoring stack — Wave 8 in our template. You need the source-side monitoring until the very end; the new AWS-side monitoring takes over only after all other waves are green.
Rollback is a layer, not a button
The single most common failure of mid-programme cutovers is the absence of a documented rollback. “If it goes wrong we’ll roll back” is not a plan. A rollback layer is:
- Trigger conditions written in advance: error rate > X% of baseline for ≥ 15 min, p95 latency > Y ms, replication-back-to-source fails, SEV-2 customer incident.
- Steps written for the specific workload, not a generic playbook: which DNS records flip, which application config reverts, what queued writes replay, who approves the call.
- Window: how long the source remains warm and capable of taking traffic post-cutover. 30 days minimum for medium criticality, 60 for high, 90 for critical.
- Decision authority: a named individual (with a named alternate) who can call rollback in the middle of the night without escalation delay.
The cutover runbook skeleton has these phases as explicit gates — T-7, T-1, T-0, T+1, T+7, T+30. Copy the file per wave, fill in the specifics, and test the rollback path in a non-production environment at least once before any high-stakes wave.
What broke — Wave 4 (BI + analytics) cutover, around 23:00 UTC. The SQL Server source-side replication lag dashboard had been green for 6 weeks, but the dashboard was reading the target side only. Real source-side lag had drifted to ~90 minutes when traffic was redirected, and the BI reports ran against the target showed materially stale numbers for 90 minutes after cutover. Detected when the morning finance team noticed reporting numbers from the previous day were missing. Rollback was invoked at T+2h (DNS reverted to on-prem source, replication queue drained to target over the next 5 days). Mitigation: every subsequent wave shipped with lag monitors on both source and target plus a hard pre-cutover gate of ”< 60s lag for 30 min” as a go/no-go condition. The pattern is now in the risk register as Risk #2.
What to do this week
- Read the colo lease end-to-end and identify the notice clauses. Build the master timeline backwards from the notice date, not the lease-end date.
- Pull a list of every workload running in the DC. Score each on criticality (low/medium/high/critical) and dependency depth (count of inbound + outbound network flows). This is the input to wave assignment.
- Open the wave plan template and group your workloads into 6–10 waves of 8–15 workloads each. Identify out-of-scope dependencies and resolve them (move workloads to a different wave, or carve out a minimal sub-system).
- Open the risk register. Add owners and dates to every row. Re-prioritise per your estate.
- Copy the cutover runbook skeleton for Wave 1 and fill in the specifics. Test the rollback path in a non-production environment before scheduling the cutover window.
- Brief executive sponsors with the 21-month timeline and the budget envelope from the wave plan. Get explicit approval for the 90-day decom window on critical waves — that is where lease cost meets rollback risk.
What this post doesn’t cover
- Multi-cloud DC exits — moving workloads to AWS and a second hyperscaler simultaneously. Different programme shape, different vendor management.
- Mainframe re-hosting — a specialist programme of its own (z/OS → AWS Mainframe Modernization or partner-managed); the wave model does not fit cleanly.
- HR / staffing ramp for the programme team — sizing the team, contractor strategy, knowledge transfer.
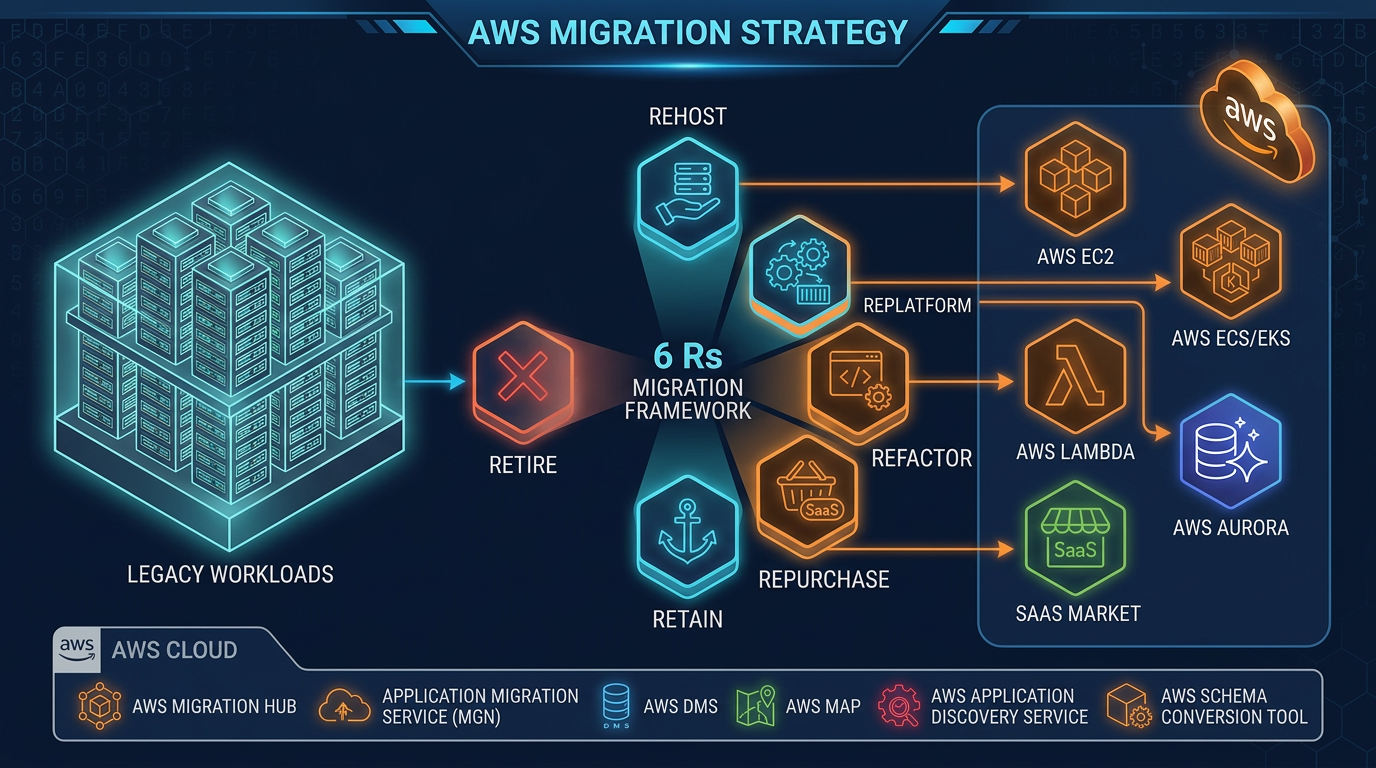
- Detailed migration strategy decisions per workload — the 7Rs framing is covered in the existing strategy post.
- MAP funding mechanics in 2026 — eligibility, milestones, and credit application — covered separately.
- Migration cost surprises during dual-run and steady-state — covered in the existing FinOps-for-migration post.
- Cloud exit from AWS — see the cloud exit and reversibility post; reversibility is not the same problem as DC exit.
Related: Cloud migration consulting · Migration readiness checklist · Post-migration optimization & FinOps handoff · Migration without cost surprises · Cloud exit and reversibility
If you only do one thing: Build the master timeline backwards from the notice date in your colo lease, not the lease-end date. Many exits stall not on technology but on a notice clause discovered in month 14.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.