Observability Beyond CloudWatch (2026): When to Add Application Signals, ADOT, Managed Prometheus, and Grafana — and When Not To
Quick summary: The reflex to bolt Amazon Managed Prometheus + Grafana onto every workload is how observability bills quietly double. CloudWatch Application Signals now gives you an auto-discovered service map, SLOs, and traces with near-zero setup; AMP only earns its keep when you are PromQL-native or drowning in high-cardinality metrics — where ingestion (not retention) is the cost driver. Here is the decision matrix, an ADOT dual-export config, and the three levers that actually cut the AMP bill.
Key Takeaways
- The reflex to bolt Amazon Managed Prometheus + Grafana onto every workload is how observability bills quietly double
- The fastest way to double an AWS observability bill in 2026 is to bolt Amazon Managed Prometheus and Grafana onto a workload that CloudWatch Application Signals would have covered
- 0
- 0 in May 2025)
- Benchmark pattern (not a cited client) — A composite Kubernetes-heavy platform: ~40 microservices on EKS, an existing Prometheus + Grafana habit, and a "scrape everything at 15s" default
Table of Contents
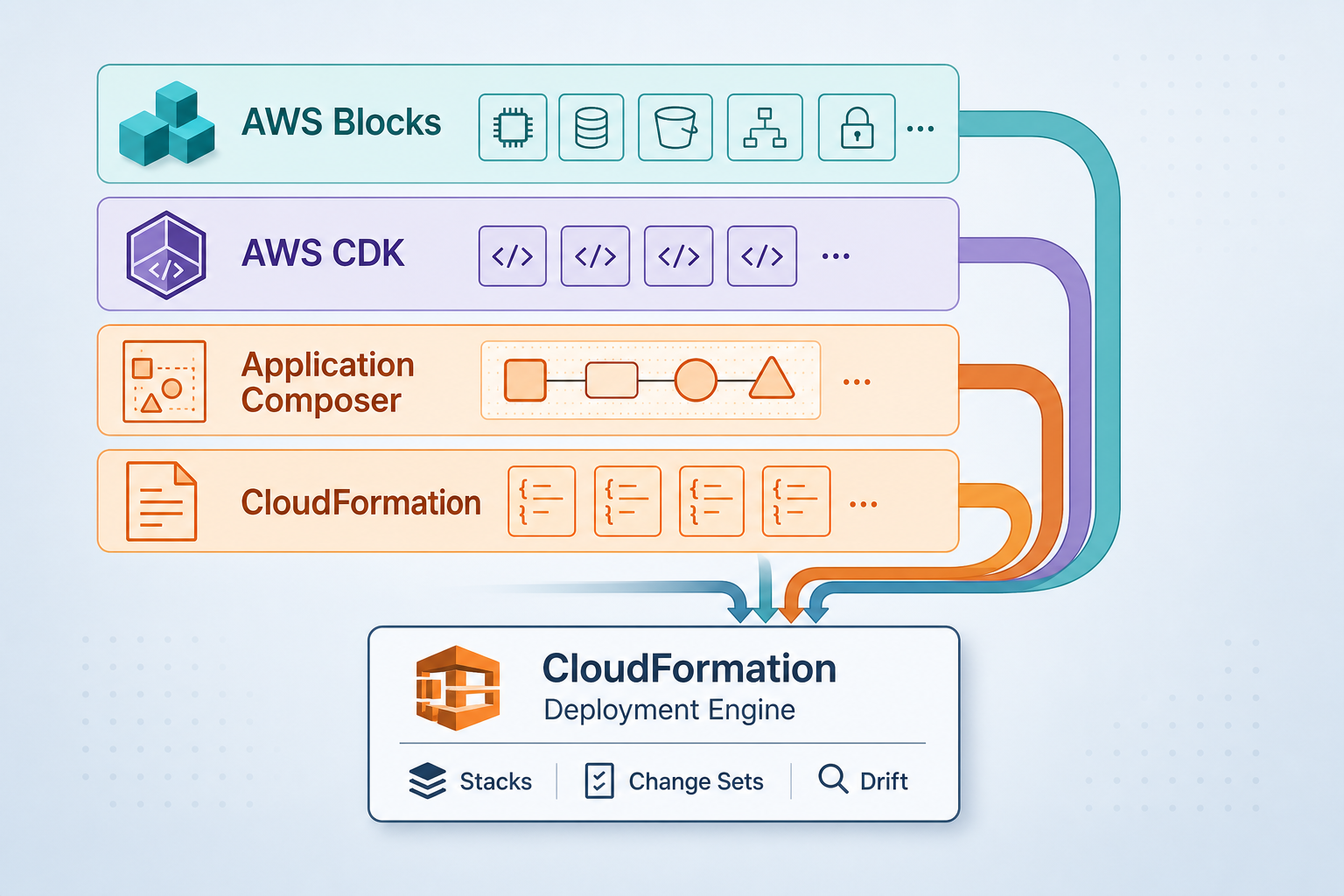
The fastest way to double an AWS observability bill in 2026 is to bolt Amazon Managed Prometheus and Grafana onto a workload that CloudWatch Application Signals would have covered. As of mid-2026, CloudWatch Application Signals gives you an auto-discovered service map, SLOs, and correlated traces with near-zero instrumentation — features that landed and matured across 2024–2025 (dependency SLOs in April 2025, multi-account views via OAM in February 2025, EKS auto-monitor in the CloudWatch Observability add-on v4.0.0 in May 2025). Yet the reflex is still to stand up a second metrics backend “for real observability.” Sometimes that’s right. Often it’s a second billing surface and a second query language for no measured gain. This post is the decision framework, not a tutorial on any one tool.
Symptom → mechanism → AWS control
| Production symptom | Mechanism | AWS control |
|---|---|---|
| Can’t correlate traces to logs | Siloed CloudWatch log groups | ADOT collector with trace context propagation |
| Missing service dependency map | No distributed tracing | X-Ray or OTel → CloudWatch Application Signals |
| Prometheus ops burden | Self-managed scrape + storage | Amazon Managed Prometheus (AMP) + Managed Grafana |
Opinionated take: Stay on CloudWatch until you need cross-service RED metrics or PromQL—then ADOT → AMP, not self-hosted Prometheus on EC2.
This is for platform and SRE teams, and the engineering leaders signing the observability invoice. We ship a tier decision matrix, an ADOT dual-export collector config, the three AMP cost-control levers, and an AMG/AMP cost model CSV.
Benchmark pattern (not a cited client) — A composite Kubernetes-heavy platform: ~40 microservices on EKS, an existing Prometheus + Grafana habit, and a “scrape everything at 15s” default. Modeled in the cost CSV: moving non-alerting infra series from 15s to 60s cuts those samples ~60%, and adding source-side metric filtering takes the relative ingestion index from 100 → ~22 — roughly a 4–5x reduction in the dominant AMP cost driver, with no loss of alerting fidelity. Separately, switching 8 dashboard-only engineers from Grafana Editor ($9) to Viewer ($5) trims AMG user cost by ~44% on that slice. Neither change touches retention, because storage isn’t where the money is.
Tier 1: CloudWatch core is the floor, not a placeholder
If you need logs, metrics, alarms, and Logs Insights over AWS services, CloudWatch core is the answer — don’t add a second stack for it. The cost traps here are well-trodden: high-cardinality custom metrics and verbose log ingestion. Those are real, but they are CloudWatch hygiene problems, not reasons to migrate to Prometheus. (We cover that hygiene in depth in observability FinOps and cardinality cost control and CloudWatch logging costs.)
Tier 2: Application Signals is the APM you probably already have
The moment you want APM — a service map, SLOs, “which dependency is breaking my latency” — the default should be CloudWatch Application Signals, not a new backend. It auto-discovers services and dependencies, draws the application map, tracks period- and request-based SLOs (including SLOs on dependencies since April 2025), and correlates traces so you can drill from a fault-rate summary to the offending span.
It auto-instruments across EKS, EC2, ECS, Kubernetes, Lambda, and on-prem, and ingests OpenTelemetry via ADOT and the CloudWatch agent. Setup gotcha: you must enable Transaction Search to unlock the full APM feature set under the unified Application Signals pricing that bundles X-Ray traces and transaction spans. On EKS, the CloudWatch Observability add-on (v4.0.0+) can auto-monitor workloads behind a single config flag.
Service Events (July 6, 2026): once Application Signals is enabled, AWS automatically captures exception/latency snapshots and deployment events for Java, Python, and JavaScript workloads (ADOT SDK or CloudWatch Observability EKS add-on) — useful for answering “did this deploy introduce new errors?” without bolting on a second APM. Function-call metrics remain opt-in.
Opinionated take: most teams reaching for “we need APM, let’s deploy Grafana Tempo + a tracing backend” should enable Application Signals first and measure whether the gap is real. It usually isn’t.
Tier 3: ADOT + Managed Prometheus + Grafana — earn it
Step up to ADOT + Amazon Managed Service for Prometheus (AMP) + Amazon Managed Grafana (AMG) when you can name the reason:
- You’re PromQL/Prometheus-native with existing exporters and dashboards.
- You have high-cardinality metrics where Prometheus’s model beats CloudWatch custom metrics on both ergonomics and cost.
- You want OpenTelemetry-native, vendor-portable instrumentation.
- You need a single Grafana pane correlating AWS and third-party data.
AMP is serverless and Prometheus-compatible (PromQL, Multi-AZ, EKS + self-managed K8s), with default 150-day retention configurable up to 3 years. AMG is fully managed Grafana over CloudWatch, X-Ray, Prometheus, and third-party sources.
The pragmatic shape is instrument once with OpenTelemetry and dual-export — traces to X-Ray (feeding Application Signals’ service map and SLOs) and metrics to AMP (for PromQL + high cardinality). That’s exactly what the ADOT collector config does. The cost: one more component — the collector — to run and keep upgraded.
What broke — A team adopted AMP + AMG on day one for a new EKS platform “to do observability properly,” scraping every exporter at 15s and granting all 12 engineers Grafana Editor. The first month’s bill was dominated by AMP ingestion (the scrape-everything default) and inflated by paying $9/Editor for engineers who only ever viewed dashboards. Nothing was wrong — it just cost multiples of what it needed to. The fix was unglamorous: raise scrape intervals on non-alerting series, drop unused metric families at the source, and reassign 8 users to the $5 Viewer tier. The mistake wasn’t the tools; it was adopting them before measuring whether CloudWatch + Application Signals already answered the questions, then running them with no cost discipline.
The cost lever that surprises people: ingestion, not retention
AWS is explicit that metric ingestion is the largest AMP cost driver, and that cutting retention rarely helps. The three levers, in order:
- Raise the scrape interval on series that don’t need 15s resolution (60s is ~4x fewer samples for those series).
- Filter metric families and high-cardinality labels at the source — one runaway label (user ID, request ID, full URL) can multiply a series into millions.
- Pre-aggregate with recording rules — compute the p99/error-rate once instead of scanning raw series on every dashboard load (also cuts query-sample cost).
Leave retention alone unless compliance demands a change. For AMG, default users to Viewer ($5) and reserve Editor ($9) for dashboard authors.
AWS services map
| Need | Service | Skip when |
|---|---|---|
| OpenTelemetry pipeline | ADOT on EKS/ECS | Single Lambda with CloudWatch logs only |
| Prometheus-compatible storage | AMP | <5K series, CloudWatch metrics sufficient |
| Dashboards + alerting | Amazon Managed Grafana | CloudWatch dashboards meet SLO needs |
What to do this week
- Inventory which workloads have Application Signals on. Enable it (with Transaction Search) on your top revenue services before you consider any new backend.
- For each AMP/AMG workload, ask: what specific question does CloudWatch + Application Signals fail to answer? If you can’t name it, you’ve found a candidate to retire.
- Run the tier decision matrix per workload — don’t apply one stack uniformly.
- If you run AMP: apply the cost-control levers — audit cardinality, raise scrape intervals, filter at source.
- Audit Grafana licenses: reassign view-only engineers from Editor to Viewer.
What this post doesn’t cover
- CloudWatch alarm and Logs Insights fundamentals — see CloudWatch metrics, logs, and alarms best practices.
- Distributed-systems debugging workflow (how to actually use traces in an incident) — see debugging production distributed AWS systems.
- A hands-on OpenTelemetry + chaos tutorial — see the OTel demo game post.
- Amazon Managed Grafana workspace ops (Grafana 12.4 upgrades, Viewer-default seats, NAC/VPC, CMK, service-account hygiene) — see Amazon Managed Grafana workspace best practices (2026).
- Loki/log-analytics backends and Grafana OnCall — out of scope here.
- Exact current pricing — confirm AMP per-sample rates and AMG per-user rates on the respective AWS pricing pages; figures here are the mid-2026 model.
Related: CloudWatch observability best practices · Observability FinOps & cardinality cost control · CloudWatch logging costs · Debug production distributed systems · AWS managed services
If you only do one thing: Before standing up any new metrics backend, enable CloudWatch Application Signals with Transaction Search on your top services and ask what question it fails to answer. If you can’t name the gap, you don’t need the second stack — and you’ve just avoided doubling the bill.
More in This Track
Part of the Engineering Guides library (June 2026).
- Next: Part 2
- Browse tracks: Engineering Guides hub
Related reading
- The AWS CLI Bug That Broke /dev/null Across Your Entire System
- AWS Environment Parity: Why Dev/Staging/Prod Drift Costs More Than It Saves
- What DevOps Guides Don
- DevOps on AWS: CodePipeline vs GitHub Actions vs Jenkins
- Two Free LocalStack Alternatives in 2026: MiniStack vs floci
- The Terraform Command Cheat Sheet for AWS Engineers (2026 Edition)
- How to Build Ultra-Fast Asset Pipelines with Bun, Vite, and Rust-Based Tooling (2026)
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.