AWS DevOps & Platform Maturity Model (2026): A 4-Level Scorecard Anchored to Real Services
Quick summary: Generic DevOps maturity models score you on culture slides — this one maps L1–L4 to AWS gates you can verify: IaC in Git, GitOps or gated CD, ADOT on EKS, FIS with stop conditions, and cost-aware CI. A composite 85-engineer SaaS moved from L2 to L3 in one quarter by fixing the CI/GitOps boundary alone, cutting deploy-related incidents from ~6/month to 2.
Key Takeaways
- Generic DevOps maturity models score you on culture slides — this one maps L1–L4 to AWS gates you can verify: IaC in Git, GitOps or gated CD, ADOT on EKS, FIS with stop conditions, and cost-aware CI
- A composite 85-engineer SaaS moved from L2 to L3 in one quarter by fixing the CI/GitOps boundary alone, cutting deploy-related incidents from ~6/month to 2
- On June 11, 2026, most AWS platform teams do not have a maturity problem — they have a measurement problem
- This post is a four-level, AWS-anchored maturity model for platform and DevOps programs
- It is not a replacement for 10 AWS DevOps practices we use in production — that post is what to do

Table of Contents
On June 11, 2026, most AWS platform teams do not have a maturity problem — they have a measurement problem. Leadership asks for “DevOps maturity” and gets a CMMI worksheet or a DORA dashboard with deploy frequency and lead time, but no answer to the operational question: what do we build next quarter, and how do we know it worked? AWS has shipped concrete platform primitives since re:Invent 2024 — declarative policies for durable EC2/VPC/EBS baselines, Resource Control Policies through February 2026 (including DynamoDB), ADOT as an EKS add-on, and FIS scenarios integrated with AWS Resilience Hub — but those land as feature announcements, not as levels on a scorecard.
This post is a four-level, AWS-anchored maturity model for platform and DevOps programs. It is not a replacement for 10 AWS DevOps practices we use in production — that post is what to do. This one is where you are and what to do next, with a downloadable scorecard and 90-day upgrade template.
Benchmark pattern (not a cited client) — Composite B2B SaaS, ~85 engineers, 4 AWS accounts (no OU guardrails), Terraform in Git but
terraform applyfrom engineer laptops to staging, CI that ran tests and thenkubectl applyto a shared EKS cluster. Representative shape: ~6 deploy-related incidents/month (wrong image, drifted config, rollback that did not stick). One quarter focused only on the L2→L3 delivery gate — CI builds and opens PRs; Argo CD reconciles;kubectl applyremoved from pipeline — incidents dropped to ~2/month without changing instance sizes or adding headcount. The lever was measurement and boundary, not a new tool category.
The four levels (AWS gates, not adjectives)
| Level | Name | You know you’re here when… | AWS anchors |
|---|---|---|---|
| L1 | Ad-hoc | Console changes; no single deploy path; on-call learns about prod from users | Single account; CloudWatch optional |
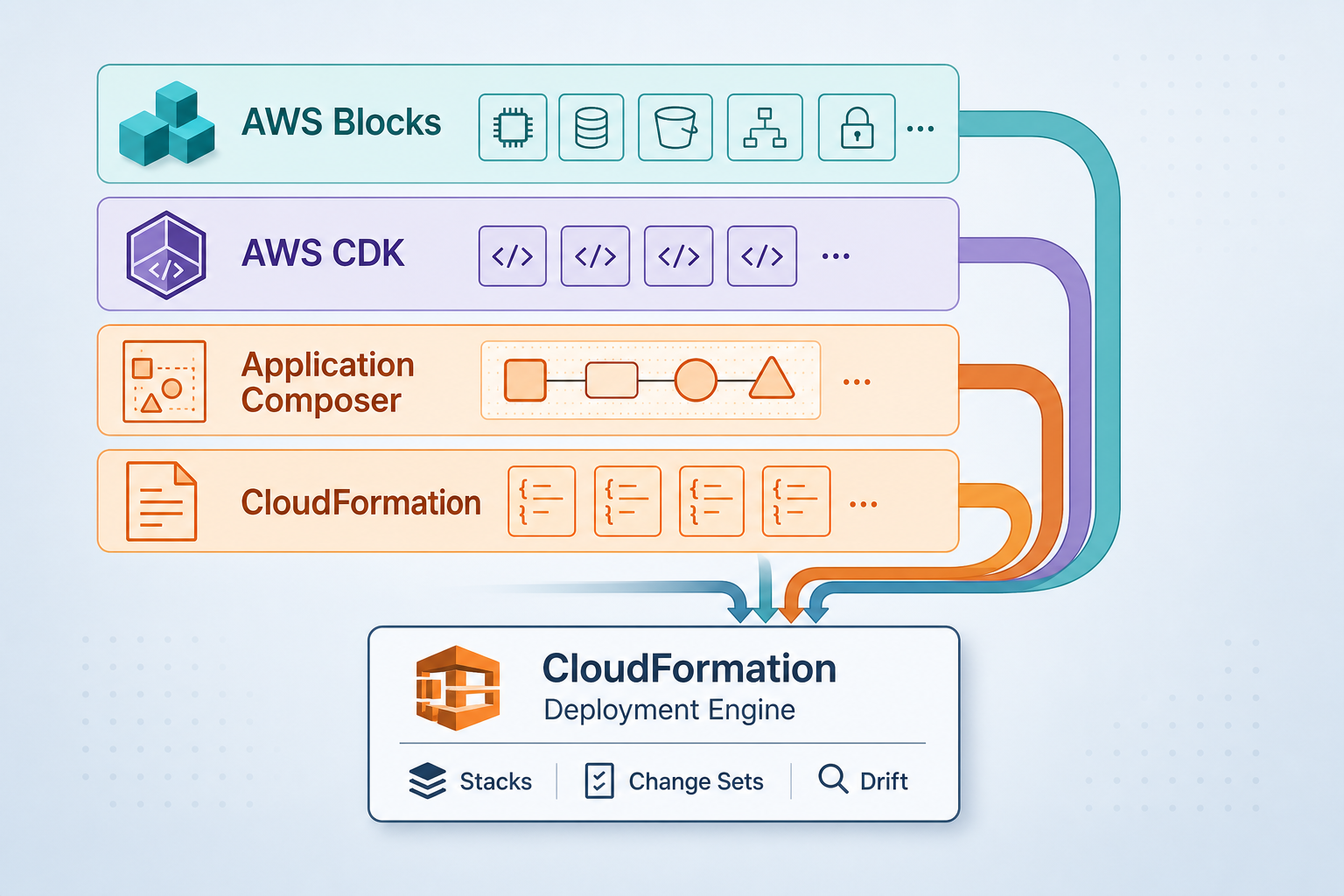
| L2 | Repeatable | IaC in Git; CI builds/tests; deploy is manual, scripted, or pipeline-push | CodePipeline/GitHub Actions; Terraform/CDK; basic alarms |
| L3 | Managed | One writer to prod (GitOps or gated CD); multi-account LZ; app traces/metrics on tier-1 | EKS + Argo CD/Flux; Control Tower or LZA; ADOT; Config rules; Organizations SCPs |
| L4 | Optimizing | SLOs/error budgets; scheduled FIS with stop conditions; cost in CI; self-service golden paths | FIS + Resilience Hub; AMP/AMG or App Signals; tag policies + anomaly detection; IDP/templates |
Opinionated take: score per capability, not one number for the whole org. It is normal to be L3 on CI/CD and L1 on resilience — that honesty is the point.
Score yourself (use the artifact)
Download the maturity scorecard CSV. Eight capabilities:
- IaC foundation — versioned infra, drift awareness
- CI/CD delivery — who writes to prod?
- Multi-account — landing zone vs account sprawl
- Observability — infra metrics vs service SLOs
- Security shift-left — secrets, OIDC, scanning
- Resilience — hope vs FIS program (maturity matrix for FIS specifically)
- FinOps in platform — tags, chargeback, cost-aware CI
- Self-service — tickets vs golden paths
For each row, pick current and target level. If you cannot link evidence (pipeline URL, SCP ID, experiment template), pick the lower level.
The L2 → L3 jumps that actually move incidents
1. Delivery: one writer to production
If CI and a human can both change prod, you are L2. L3 requires exactly one reconciler — GitOps on EKS or gated CodePipeline/CodeDeploy. See the GitOps post for the five traps; the maturity lens is simple: can a Git revert roll back prod? If not, stay L2 until fixed.
2. Multi-account: policy follows OU
L2 is “we have multiple accounts.” L3 is OU structure + baseline SCPs via Control Tower or equivalent, plus day-2 sharing patterns. Declarative policies (GA December 2024) belong in the platform baseline — not hand-maintained SCP denylists per API.
3. Observability: ADOT or equivalent on Kubernetes
L2 is CPU and 5xx alarms. L3 is traces + service metrics — on EKS, the ADOT add-on is the supported path to CloudWatch, X-Ray, and AMP. Deep dive: observability beyond CloudWatch.
4. Resilience: one scheduled FIS experiment
L3 resilience is not “we will do chaos someday.” It is one FIS template with CloudWatch alarm stop conditions, run on a schedule in non-prod, documented steady-state hypothesis. L4 adds prod GameDays and pipeline gates — see FIS resilience program.
What broke — A team scored themselves L3 on CI/CD because they “used Argo CD.” Under audit: CI still ran
helm upgradeon merge tomain, and Argo CD reconciled the same chart from a different branch. Two writers, weekly drift, rollbacks that “succeeded” in Git but not in cluster. They dropped to an honest L2, removedhelm upgradefrom CI, and re-scored L3 six weeks later. Tool installed ≠ level achieved.
90-day upgrade (one capability only)
Use the level-up roadmap template. Rules:
- One capability level-up per quarter
- Weeks 1–2: baseline metrics only — no new tools
- Weeks 3–6: working change in non-prod
- Weeks 7–12: prod (tag-scoped) + re-score
Trying to jump IaC + GitOps + FIS + FinOps in one quarter is how programs die at L2 forever.
What to do this week
- Download the scorecard and fill current levels with evidence links.
- Pick one L2→L3 row — usually
cicd_deliveryormulti_account. - Run the delivery audit: does any human or CI job bypass the reconciler? If yes, that is this quarter’s project.
- Schedule a 60-minute re-score in 90 days — same attendees, same CSV.
What this post doesn’t cover
- Workload-level Well-Architected reviews — use WAFR for depth on a single system.
- DORA metrics benchmarking — we use levels here; you can map deploy frequency to levels separately.
- Full GitOps or FIS tutorials — see linked pillar posts.
- Team topology / platform org design — see CCoE operating model.
Related: DevOps pipeline setup · 10 AWS DevOps practices · GitOps on EKS · Cost-aware CI/CD
If you only do one thing: Score cicd_delivery honestly. If two systems write to production, fix that before buying any other platform tool.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.