Amazon Bedrock AgentCore Pricing: The 12 Components Behind Your Agent Bill
Quick summary: Bedrock AgentCore is metered across twelve distinct components — Runtime, Browser, Code Interpreter, Gateway, Identity, Memory (two tiers), Observability, Evaluations, Payments, Search, and the underlying model spend. Two of them drive 80% of the bill.
Key Takeaways
- Two of them drive 80% of the bill
- AWS lifecycle notice (June 30, 2026) — Amazon Bedrock Agents Classic is now Bedrock Agents Classic, in maintenance for new customers after July 30, 2026
- Net-new agent builds should use Bedrock AgentCore
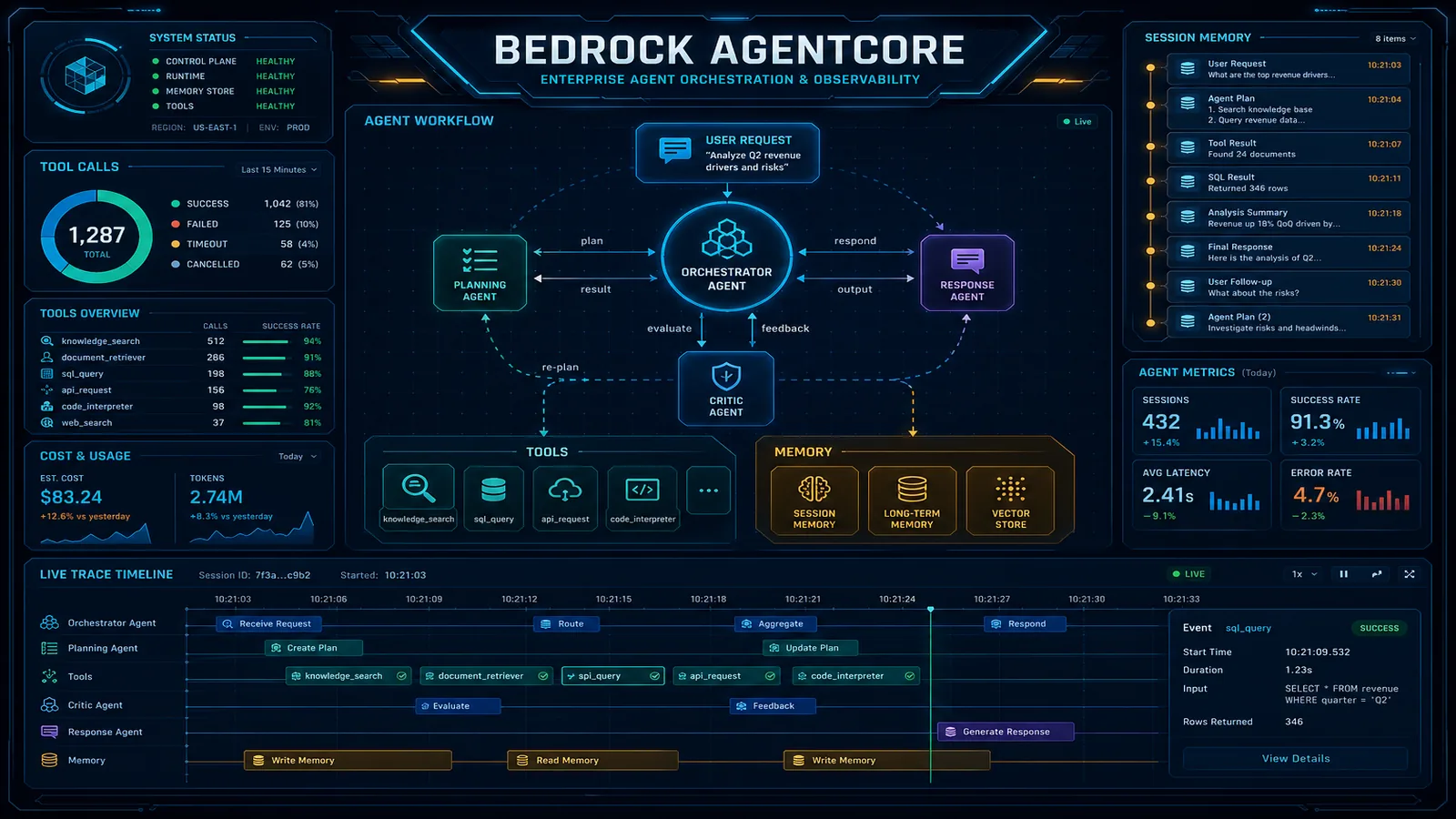
- astro'; Amazon Bedrock AgentCore is the modular production platform for net-new agents (Harness, Runtime, Memory, Gateway, Identity, and related services) — not a thin wrapper around Agents Classic
- Work the numbers on the AgentCore pricing calculator (list rates as of 2026-07-04, us-east-1)

Table of Contents
AWS lifecycle notice (June 30, 2026) — Amazon Bedrock Agents Classic is now Bedrock Agents Classic, in maintenance for new customers after July 30, 2026. Net-new agent builds should use Bedrock AgentCore. Full matrix: lifecycle roundup.
Amazon Bedrock AgentCore is the modular production platform for net-new agents (Harness, Runtime, Memory, Gateway, Identity, and related services) — not a thin wrapper around Agents Classic. The architecture story is in our AgentCore production guide. This post is the bill story — twelve distinct metered components, what each one charges for, which two of them quietly dominate the invoice, and how to model the spend before the first session. Work the numbers on the AgentCore pricing calculator (list rates as of 2026-07-04, us-east-1).
Amazon Bedrock AgentCore pricing meters twelve components — Runtime, tools, Memory, and more — on top of underlying model token spend. In us-east-1 (July 2026), Runtime active compute (vCPU/GB-hour) and long-term Memory events/retrievals are the dominant lines for most production agents. Most surprises come from cross-session Memory growing without a retention TTL.
| Component | Typical bill share | Primary trap |
|---|---|---|
| Bedrock model tokens | Largest line | Model choice dominates |
| Runtime active compute | ~15–22% of model spend | Tool latency extends billed seconds |
| Long-term Memory | ~6–10% of model spend | No TTL on cross-session facts |
| Browser / Code Interpreter | ~3–6% each | Enabled for every turn |
AgentCore went generally available with a metered-component pricing model that AWS has been incrementally adjusting through 2026. The pricing page reflects the current rates per region; the structure below is what stays stable across rate changes.
What Are the 12 Bedrock AgentCore Pricing Components?
Bedrock AgentCore bills across twelve distinct lines. Eleven are AgentCore-specific; the twelfth — the underlying Bedrock model spend — is what your agent calls into and is metered separately on the Bedrock model invocation rate sheet.
The 12 AgentCore-attributable line items
Prices in us-east-1
Pricing structure aligned with the AgentCore calculator (2026-07-04, us-east-1 list). Verify exact unit prices against the AWS Bedrock AgentCore pricing page for your region.
Runtime compute
DominantList: $0.0895/vCPU-hr + $0.00945/GB-hr (calculator, 2026-07-04)
- Unit price
- vCPU-hour + GB-hour (active session time)
- Example workload
- 500K sessions × ~4s active × configured vCPU/GB
Runtime session volume
Co-dominantBrowser / Code Interpreter time extends billed seconds
- Unit price
- Sessions × active seconds (drives compute)
- Example workload
- Tool-heavy agent averaging 4s/turn
Browser tool
ModerateManaged Chromium; model as minutes × vCPU/GB
- Unit price
- Same compute shape on browser minutes
- Example workload
- Research agent, 8 page loads / 90s per turn
Code Interpreter
ModerateSandboxed Python/JS/TS execution
- Unit price
- Same compute shape on sandbox seconds
- Example workload
- Data-analysis agent, 12s sandbox / turn
Gateway invocation
Low–ModerateOnly billed when you route tools via Gateway
- Unit price
- Per 1k invokes (+ search + tool index)
- Example workload
- Policy-mediated tool routing, 3 calls/turn
Identity (OIDC/JWT)
LowOnly billed when AgentCore Identity handles auth
- Unit price
- Per authenticated principal-session (opt-in)
- Example workload
- B2B agent with SSO, 12K sessions/day
Memory — short-term (in-session)
Low–ModerateCalculator: $0.25/1k STM events (2026-07-04)
- Unit price
- Per 1k STM events
- Example workload
- Conversation events within a session
Memory — long-term (cross-session)
Dominant at scaleGrows without retention/TTL; calculator $0.75/1k LTM + $0.50/1k retrieval
- Unit price
- Per 1k LTM events/month + per 1k retrievals
- Example workload
- 500K users × 30 facts × monthly recall
Observability traces
Low (often free tier)OTEL-compatible → CloudWatch; ingest after free tier
- Unit price
- Per million trace events (free tier)
- Example workload
- Full step traces on every session
Evaluations
Low (CI/CD usage)Optional automated quality scoring
- Unit price
- Per evaluation run + judge model spend
- Example workload
- Nightly regression on 200 prompts
Payments mediation
Use-case specificSpecialized; only for agents that move money
- Unit price
- Per transaction mediated
- Example workload
- Commerce agents settling on user behalf
Search (Gateway semantic / retrieval)
ModerateDistinct from Bedrock Knowledge Bases retrieval
- Unit price
- Per 1k Gateway search queries
- Example workload
- Tool discovery at 200K searches/month
The 12th line — Bedrock model invocation — is billed separately on the per-model token rate sheet and typically dwarfs all AgentCore lines combined. Calculator rates: see /tools/amazon-bedrock-agentcore-pricing-calculator/.
If you only audit one dimension first, start with long-term Memory retention — it compounds silently while user counts stay flat.
The Two Lines That Quietly Dominate
In typical production AgentCore deployments, two components consistently drive 75–85% of the AgentCore-attributable spend. Knowing which two collapses the optimization problem from twelve dimensions to two.
Runtime (active compute)
Every agent session burns active seconds on Runtime, metered as vCPU-hour + GB-hour (same shape for Browser and Code Interpreter session time). Session count is fixed by the product — you cannot reduce it without reducing user interactions. What you can reduce is average active seconds per session and the vCPU/memory footprint you configure. Three factors compound it:
- Tool latency — every Browser, Code Interpreter, or external API call extends wall-clock time, which is what AgentCore Runtime charges for.
- Self-reflection loops — agents configured to re-evaluate their own output add a second model round-trip, doubling duration.
- Verbose tool payloads — tools that return large payloads force the agent to process more tokens before responding, extending the turn.
The lever is reducing per-session active seconds and right-sizing vCPU/GB — not wishing away traffic. Streamlined Gateway tools, tighter system prompts, and disabling self-reflection for low-stakes turns are the practical moves.
Long-term Memory
Long-term Memory looks cheap per event. It compounds because every user accumulates facts forever without a TTL, and every new session retrieves the relevant slice (a separate per-1k retrieval line). A B2C agent at 500K monthly active users with 30 retained facts per user is carrying roughly 15M LTM events by month six, with retrieval traffic on every session start.
How the Bill Compounds: A Worked Example
Example workload (not from a client engagement) — consider a B2B operations agent: 250K sessions/month, average 3.2s active per turn (one Code Interpreter call + one external API call), 8K active users, 20 facts retained per user with 12-month recall. Plug the same shape into the AgentCore pricing calculator. The relative weight of each line — not absolute dollars — looks like this:
Cost contribution by line (B2B ops agent — 250K sessions/mo)
Prices in indicative
Relative cost share, not absolute dollars. Multiply your model spend by these ratios to get a directional estimate.
Bedrock model spend
100% baseline- Unit price
- Token rate × input+output
- Example workload
- Underlying model invocation
AgentCore Runtime
~15–22% of model spend- Unit price
- vCPU-hour + GB-hour
- Example workload
- 250K × 3.2s active
AgentCore long-term Memory
~6–10% of model spend- Unit price
- LTM events/mo + retrievals
- Example workload
- 8K users × 20 facts × recall
Code Interpreter
~3–6% of model spend- Unit price
- Sandbox seconds × compute
- Example workload
- ~12s per turn × 250K
Observability
~1–2% of model spend- Unit price
- Trace events past free tier
- Example workload
- Full step traces enabled
Identity, Gateway, Payments, Search
~0%- Unit price
- Each metered separately
- Example workload
- Off in this deployment
Indicative ratios from published AWS list prices and common deployment shapes (hypothetical). Always model your own workload on the calculator — multipliers shift with chat-style vs research-style traffic.
The pattern repeats across deployment shapes. Runtime + long-term Memory together land at roughly 20–30% on top of the model spend, with the remaining lines individually under 5%. This is why the first optimization passes always focus on Runtime active seconds and Memory retention — every other line item is rounding error by comparison.
Common Bill Surprises
When AgentCore Is and Is Not the Right Fit
AgentCore is the right platform when you need persistent state across sessions, audit-grade observability, Gateway Policy on tools, or managed Browser/Code Interpreter. It is not the right platform when a single-turn Converse/InvokeModel call or Knowledge Bases RAG already solves the problem — or when Amazon Quick Suite wins for employee-only knowledge work (decision guide).
Choose AgentCore when state, Gateway tools, or session isolation is non-negotiable; choose direct Bedrock APIs when the workload is single-turn and burstable.
Use when
- Agent needs cross-session memory of user preferences, project context, or prior decisions
- Regulated industry — full agent-reasoning audit trail is mandatory
- Multi-tool agent where Gateway + Policy (Cedar) gates writes before execution
- Browser-based or sandboxed-code workflows where managing the underlying infrastructure is not a core competency
- B2B agent with SSO requirements where AgentCore Identity simplifies auth
Avoid when
- Stateless single-turn Converse/InvokeModel with no recall across visits
- Internal-only agents with <20K sessions/month where Lambda + direct Bedrock is cheaper
- Employee ACL RAG where Quick Suite connectors beat a custom agent stack
- Hard sub-second first-token SLAs without warm-session design (microVM cold starts)
- Workloads where the model spend is so small that AgentCore line items would be a high relative percentage
When in doubt, prototype on Converse/InvokeModel first, then move to Harness or Runtime once persistent state, Gateway tools, or observability becomes a hard requirement.
Modeling AgentCore Cost Before You Build
The single highest-impact pre-build exercise: produce a token-volume estimate and use it as the anchor for everything else.
- Anchor on model spend. Estimate input + output tokens per turn × sessions per month × your chosen model’s per-token rate. Use the Bedrock token cost calculator to lock in the number.
- Run the AgentCore calculator. Enter sessions/month, average active seconds, vCPU, peak memory GB, Gateway volume, and Memory events/retrievals on the AgentCore pricing calculator.
- Sanity-check with multipliers. Lean Runtime-and-Memory often lands ~1.15× model spend; full Browser + Code Interpreter + Gateway + Identity closer to ~1.4×. If the calculator diverges sharply, fix your active-seconds or Memory event assumptions first.
- Layer retention. Estimate active users × retained facts × TTL. Without TTL, Memory typically lands at 5–10% of model spend at moderate scale and 10–20% at B2C scale.
- Add a 20% contingency. AgentCore line items can be adjusted by AWS between your estimate and your production date. Build in headroom.
The output is a defensible monthly cost estimate accurate within ±25% before the first production session. That accuracy is enough to make the build/buy decision and to commit to a budget envelope.
More in This Series
Part of the AWS Service Pricing series (June 2026).
- Next: Part 2
- Browse all: Cost Optimization & FinOps category
- FinOps pillar: FinOps shift-left: cost feedback in the pull request
What This Post Doesn’t Cover
- Every Identity / Evaluations / Payments unit — those lines are opt-in and less stable than Runtime/Memory; confirm on the AWS Bedrock AgentCore pricing page.
- Bedrock model spend itself — see our Bedrock cost optimization guide for token-level optimization.
- Provisioned throughput vs on-demand for the underlying model — covered separately in Bedrock provisioned throughput vs on-demand.
- Multi-region replication of long-term Memory — supported but pricing is still evolving; treat anything we wrote here as us-east-1-anchored.
- Calculator coverage gaps — the public calculator models Runtime, Browser, Code Interpreter, Gateway, and Memory; it does not yet model Identity, Observability, Evaluations, or Payments line items.
If You Only Do One Thing This Week
Set a TTL on long-term Memory items. 90 days is the right starting default for B2C agents; 180–365 days for B2B agents with intermittent user engagement. This is the single change that prevents the most common AgentCore bill-growth pattern — LTM events and retrievals silently compounding month over month with no user-visible benefit. Add a monthly compaction job that consolidates duplicate facts per user/tenant and the Memory lines stay flat regardless of user growth.
For deeper context on Harness vs Runtime, Gateway, and Identity, the AgentCore production guide walks through the same surface from the design side rather than the bill side.
AWS Cloud Architect & AI Expert
AWS-certified cloud architect and AI expert with deep expertise in cloud migrations, cost optimization, and generative AI on AWS.